วิธีการจัดการ Error Messages ให้เป็นมิตรกับทุกคนจากงาน ThoughtWorks Talks Tech
เนื่องจากยัง work from home อยู่ (และน่าจะอีกนานแน่ๆ) เห็นงาน ThoughtWorks Talks Tech จัดหัวข้อ Managing error messages ก็เลยคิดว่าเข้าไปฟังเลยดีกว่า เพราะทุกๆทีมน่าจะมีประเด็นในตรงนี้อยู่แหละเนอะ

ตัว link ของ event นี้จะอยู่ข้างล่างนี้นะ แล้วตัวคลิปย้อนหลังจะอยู่ในลิ้งนี้ด้วย จะได้หลังงานประมาณ 1 อาทิตย์


งานจะเริ่มในเวลาหนึ่งทุ่มตรง ในวันพุธที่ 28 เมษายนจ้า
พูดถึง speaker เขาหน่อยเนอะ หลายๆคนคงจะเคยคุ้นชื่อพี่คนนี้อยู่บ้าง อย่างน้อยต้องเห็น content ของพี่เขาบ้างแหละ คือคุณ Chakrit Likitkhajorn นั่นเอง ทางเราเลยขอแปะ podcast และบล็อกพี่เขาด้านล่างเลยจ้า




มาเริ่มกันเลยดีกว่าจ้า
Motivation
- การที่มีระบบที่การจัดการ error ที่ดี ทำให้สนุกและมีประสบการณ์ที่ดีในการ maintenance
- และแน่นอน เราไม่ค่อยพูดถึงในประเด็นนี้กันสักเท่าไหร่
- มีหลายๆทีมประสานงานกันในการทำงาน ในการจัดการ error ต่างๆกัน
Overview
ใน session นี้จะมีอะไรบ้างนะ
- session นี้เหมาะกับใคร มีการออกแบบ intent ยังไง และเป็นทีมลักษณะไหน
- กฏ 5 ข้อในการจัดการ error มีอะไรต้อง concern
- wrap-up ทั้งหมด
และใน session นี้จะได้ยินเสียงน้องหมาเป็นระยะ ><
Who is this talk for?
session นี้เหมาะกับคนที่ทำงานในทีมที่มี scale ใหญ่ ทำงานกับหลายๆ service อาจจะแบ่งตาม product team, business model, หรือตาม role เช่น ทีม mobile ทีม web ทีม service ทีม data science
ถ้าเป็น cross-functional team ยังไม่ค่อยเหมาะกับ session นี้ แต่รู้ไว้ก็ดี
Introduce 5 rules of managing error by storytelling
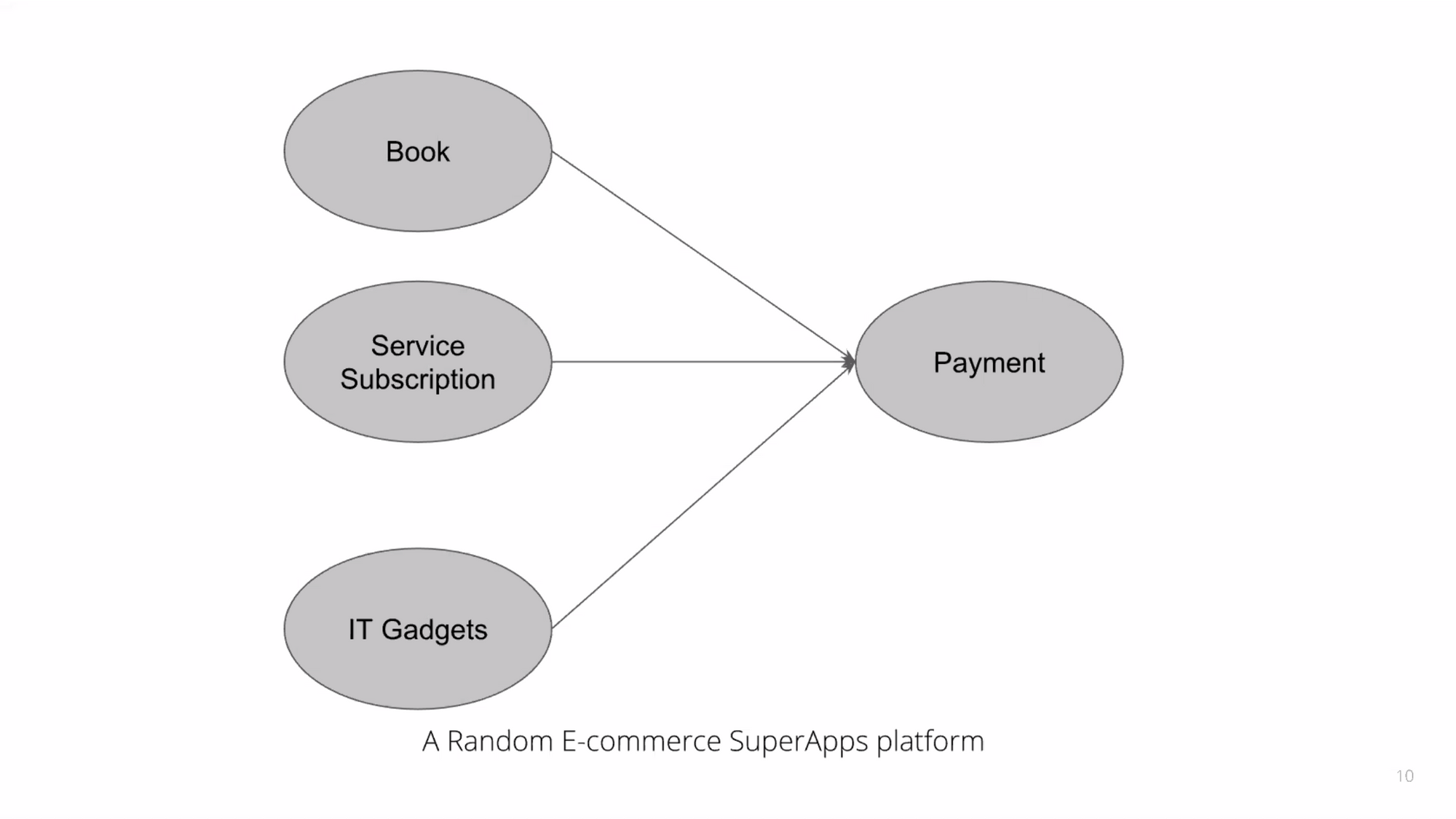
สมมุติมี E-commerce super app platform อันนึง ที่ขายหลายๆอย่างในที่เดียวกัน เช่น ขายหนังสือ, subscription ต่างๆ, ขายของ IT Gadgets และทุกๆอันจะต้องไปจ่ายเงินเหมือนกันเนอะ
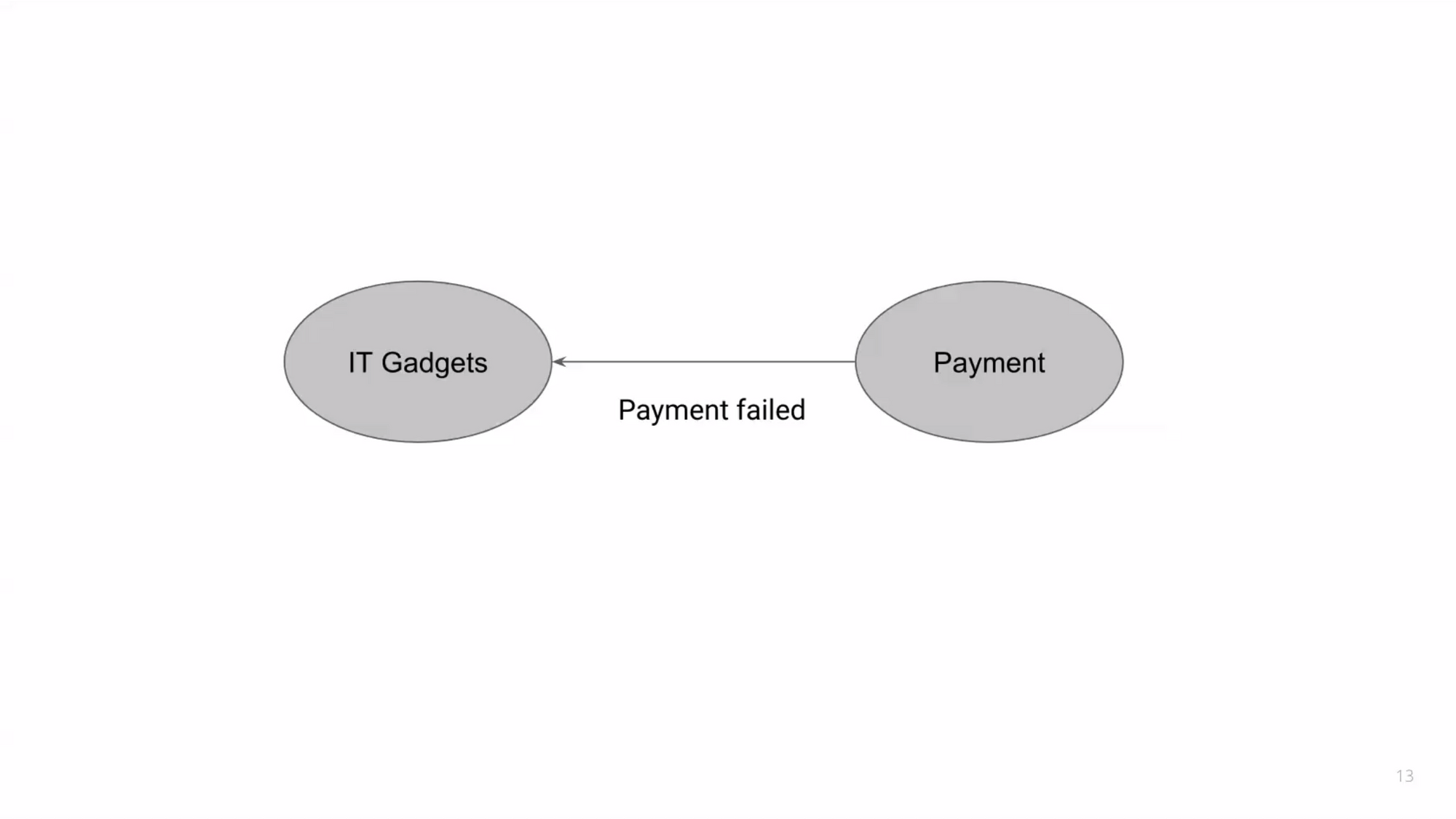
ถ้าเราตัดเป็น domain เดียว เช่น IT Gadget แล้วจ่ายเงินเนอะ แล้วถ้าจ่ายเงินไม่ผ่านจะเกิดอะไรขึ้นหล่ะ? เราก็จะไม่สามารถซื้อของได้ ก็ต้องไปกดอีกทีเพื่อจะซื้อของได้ใช่ม้า
ถ้าดูในโค้ดจะมี exception error ปกติ

คำถามคือถ้าเราเอา service นี้ไปใช้ แล้วมัน fail ขึ้นมา เราจะทำยังไงต่อ?

มี 3 ตัวเลือกให้โหวตกัน
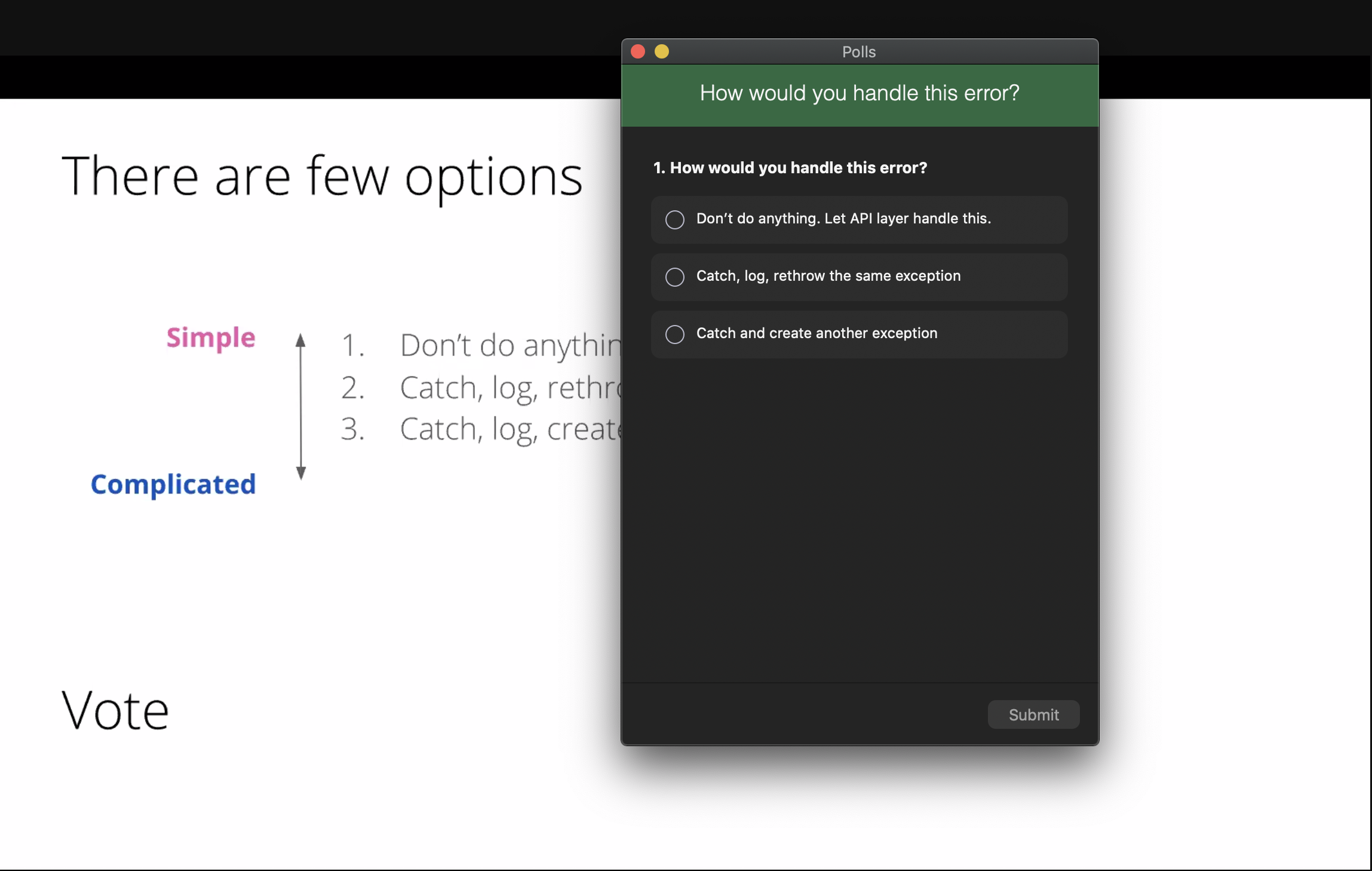
- Don't do anything. Let API Layer handle this. ไม่ต้องทำอะไร ให้ API Layer จัดการให้สิ
- Catch, log, rethrow the same exception. ทำ exception แล้วส่งกลับไปให้หลังบ้านอีกทีนึง
- Catch and create another exception. สร้าง exception ใหม่เลย
ให้คิดแปป
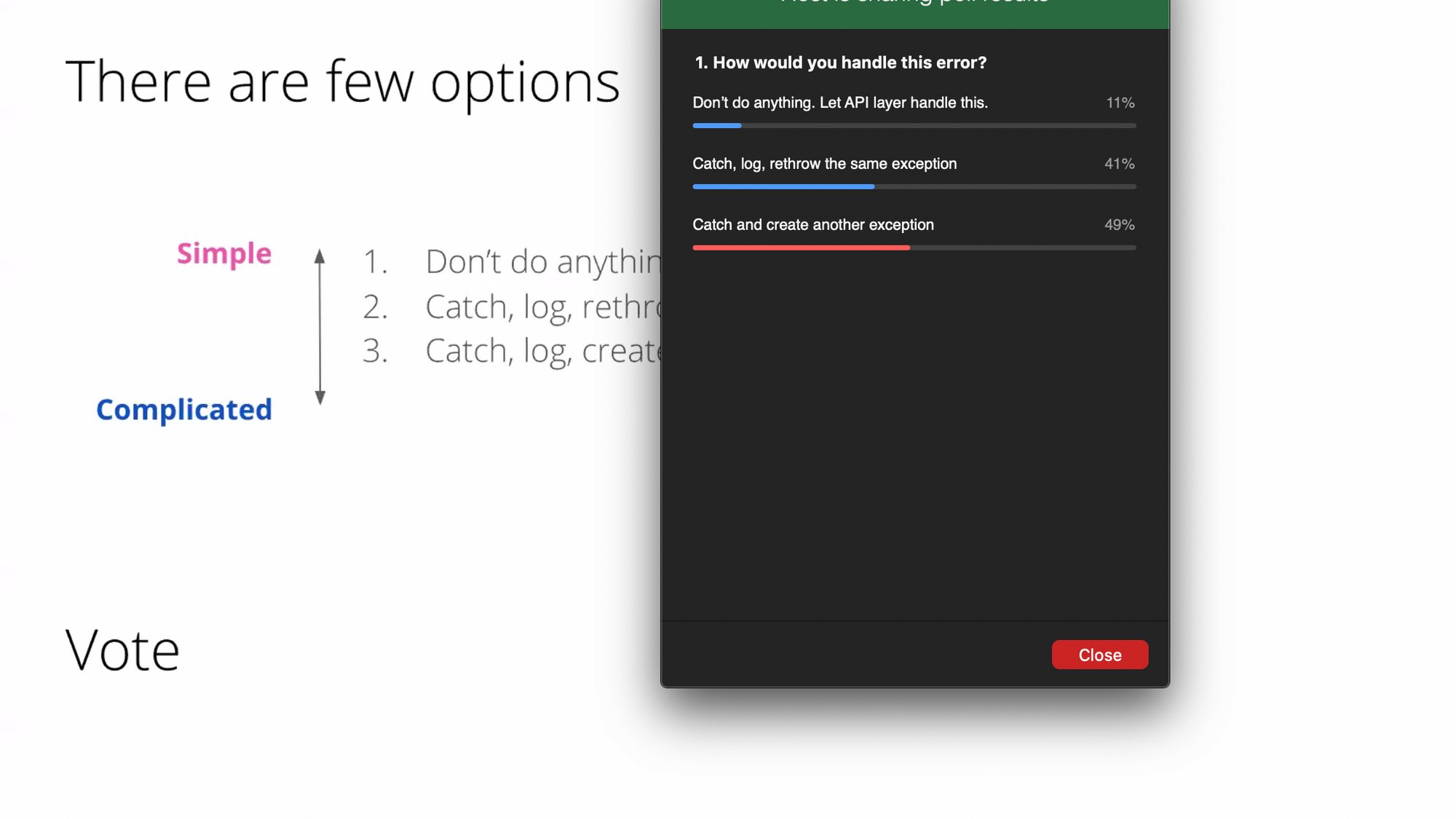
ผลโหวตก็คือ อันที่ 3 นำจ้า
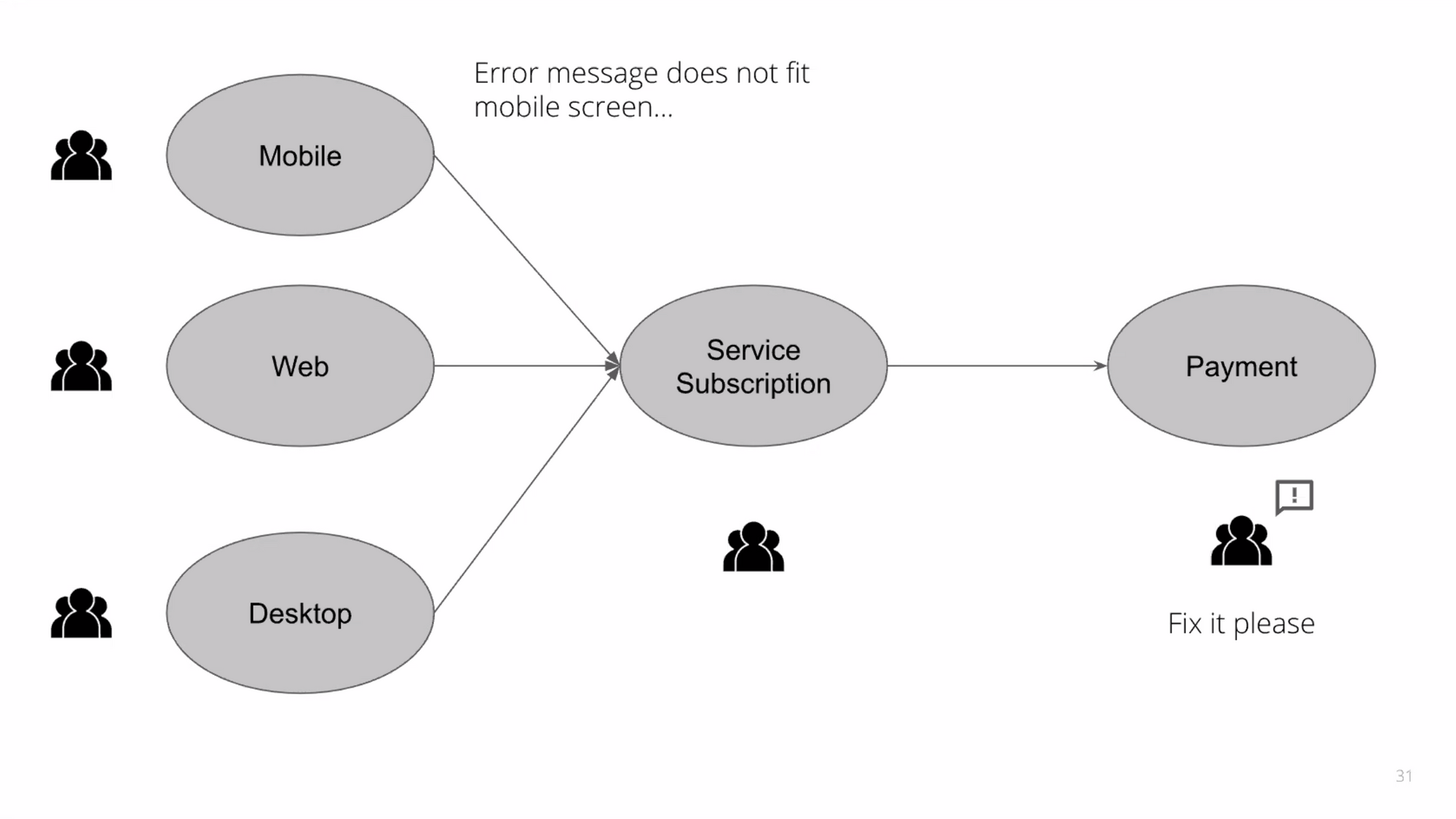
พอเรา zoom out ออกมา ถ้าในหลายๆ domain ประสบปัญหาจ่ายเงินไม่ได้หล่ะ
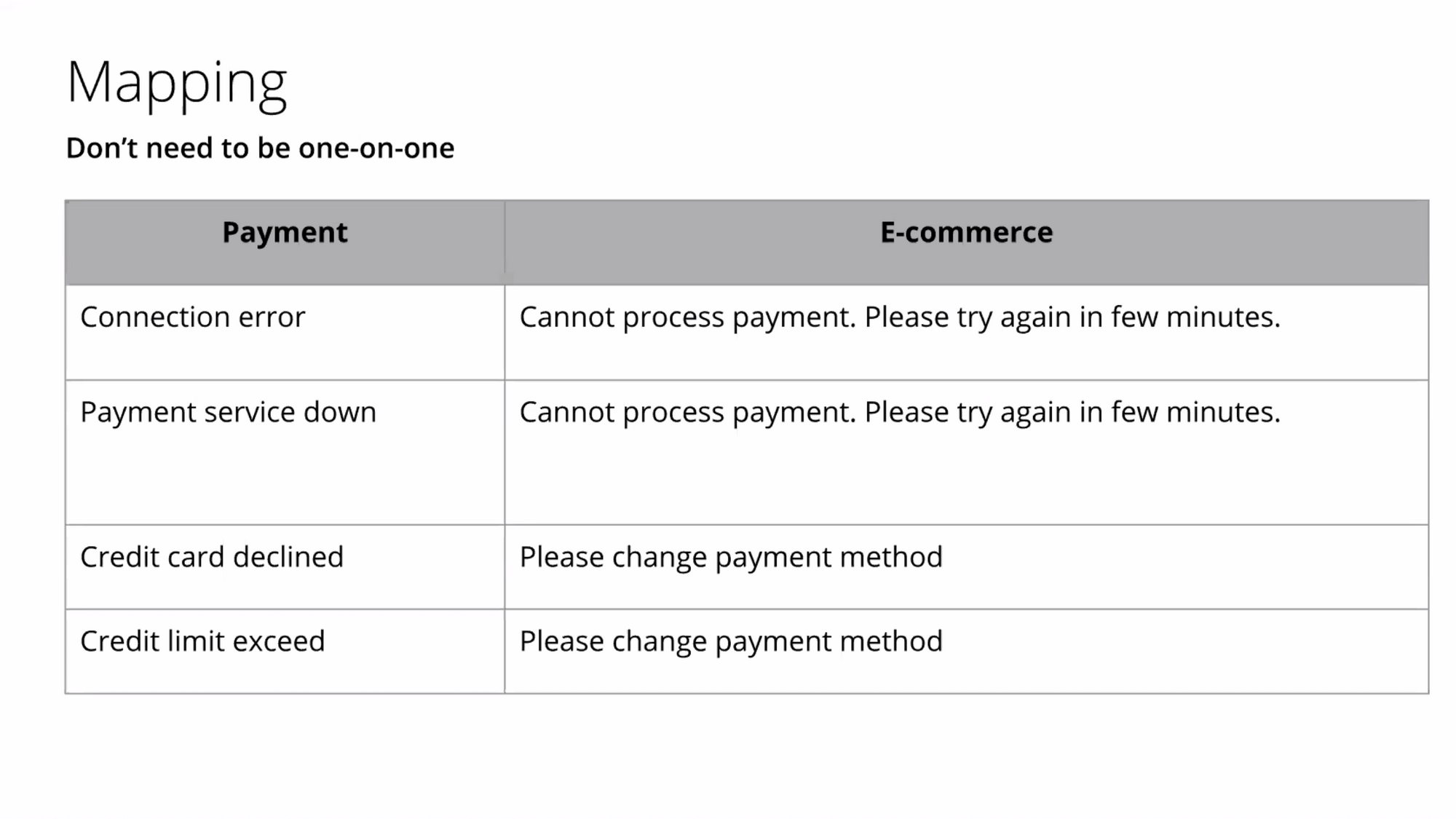
ถ้าซื้อของจ่ายเงินไม่ได้ อาจจะขึ้น Payment failed ก็คือไม่สามารถจ่ายเงินได้เนอะ ซึ่งลูกค้าเข้าใจ

แต่ถ้าพวก subscription ต่างๆอ่ะ เช่น subscription ดู content รายเดือน จะเริ่มมีความกังวลหล่ะ ว่าฉันจะต้องทำยังไงต่อไป แล้ว deadline คือเมื่อไหร่นะ ถ้าสมมุติจ่ายวันสุดท้ายแล้วจ่ายเงินไม่ได้จะโดนระงับการใช้งานไหม ดังนั้นแต่ละ domain จะมีบริบทต่างๆที่แตกต่างกัน


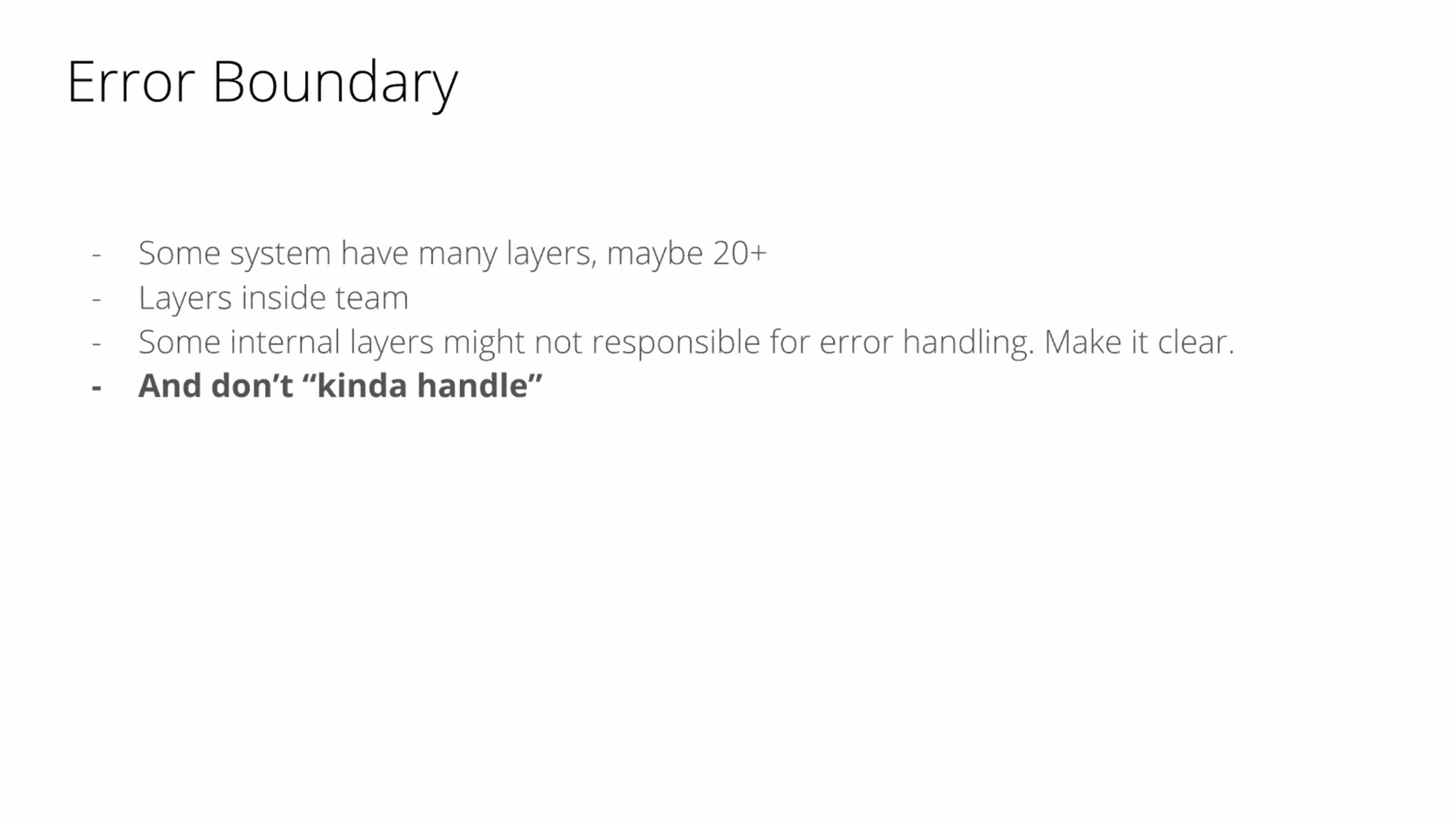
1) Draw Error Boundary
ดังนั้น เราจะต้องกำหนด error ของขอบเขตของเรา ว่าอยู่ตรงไหน และให้ลูกค้าของเราเข้าใจได้ง่ายที่สุด หน้าที่ความรับผิดชอบจะขึ้นอยู่กับสิ่งที่ลูกค้าเจอ อย่าง Techical Domain เช่น ในจอมือถือไม่สามารถดู error message ได้ ทีม mobile ควรเป็นคนแก้มากกว่าฝั่ง payment service ที่ต้องมาทำให้ support การแสดง error ในหลายๆหน้าจอมือถือ และหน้าบ้านไม่ควรใช้ downstream จาก service มาแสดงผลโดยตรง

กลับมาที่คำถามเมื่อกี้ที่ให้โหวตกัน
Option #1 : Don't do anything. Let API Layer handle this. ไม่ต้องทำอะไร ให้ API Layer จัดการให้สิ
- ข้อดี : ถูก centralized ใน domain เดียว ทำให้ระบบสามารถเห็นทุกอย่างในที่เดียว
- ข้อเสีย : ก็มัน centralized ในที่เดียวอ่ะ และต้องรู้จักทุก domain หรือทุกส่วน คน maintanance ต้องรู้จักทุกตัว
Option #2 : Catch, log, rethrow the same exception. ทำ exception แล้วส่งกลับไปให้หลังบ้านอีกทีนึง
- ข้อดี : เหมือนข้อแรก เพิ่มเติมคือได้ log มา
- ข้อเสีย : เหมือนข้อแรก และต้องระวังว่าจะมี log มากเกินไปหรือเปล่า
Option #3 : Catch and create another exception. สร้าง exception ใหม่เลย
- ข้อดี : มี ownership ในการแก้ไข
- ข้อเสีย : มันจะละเอียด เพราะแปลง error message เป็นของตัวเอง

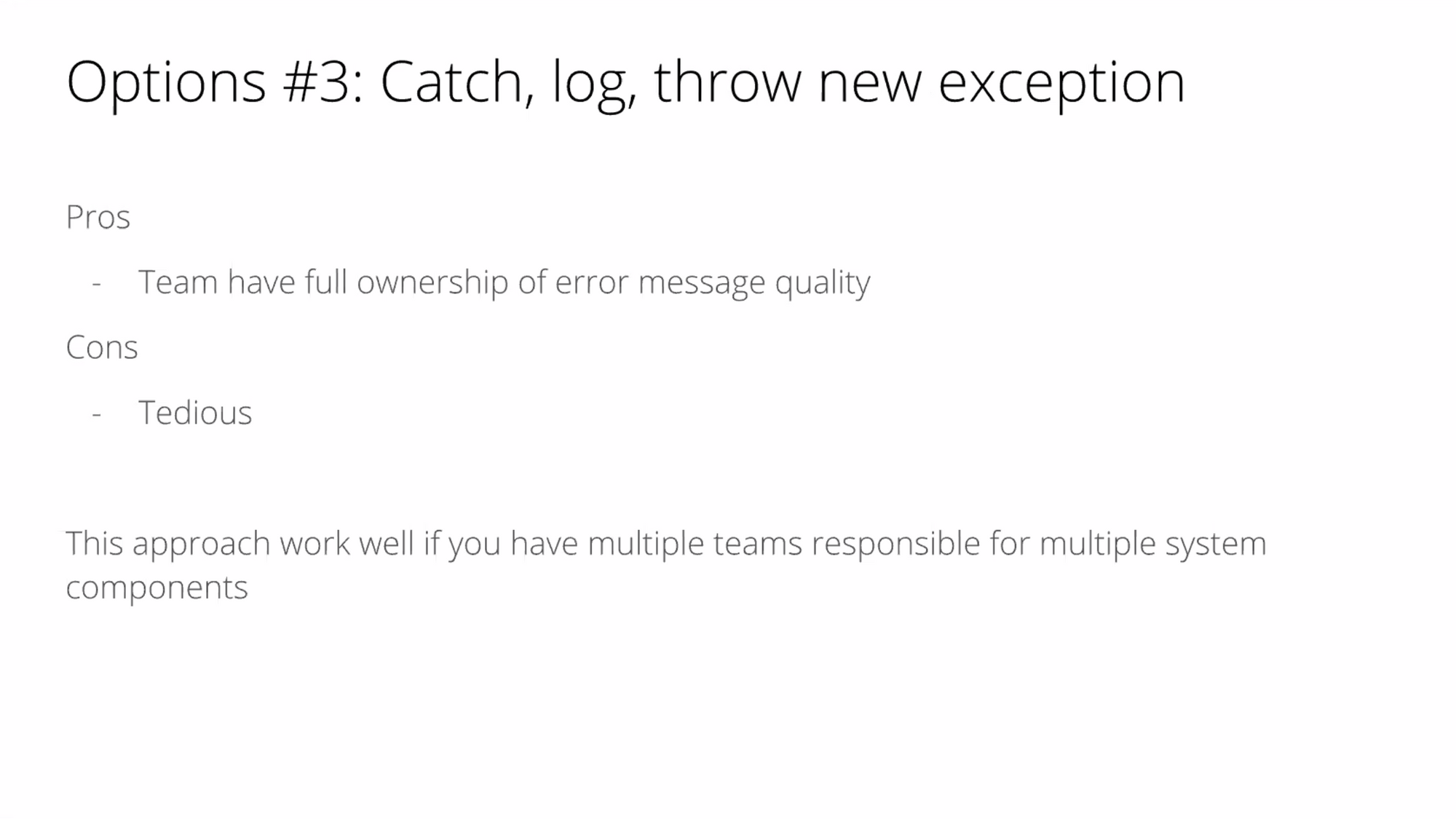
ในบริบทนี้ เป็น option 3 มีการสร้าง exception และ error message ที่เหมาะสมกับ domain ที่ตัวเองถือ

Error Boundary : ให้พยายาม handle majority ถ้ามี domain ไหนที่ไม่แปล ให้ไม่แปลไปเลย อย่างทำครึ่งๆกลางๆ ให้เขาไปดูกันเอง

ปล. ขอข้ามมุก speaker ไป กลัวคนไม่เก็ทกัน ฮืออออ
Mapping : ไม่จะเป็นต้อง map กัน 1 ต่อ 1 เสมอไป
2) Use error identifier
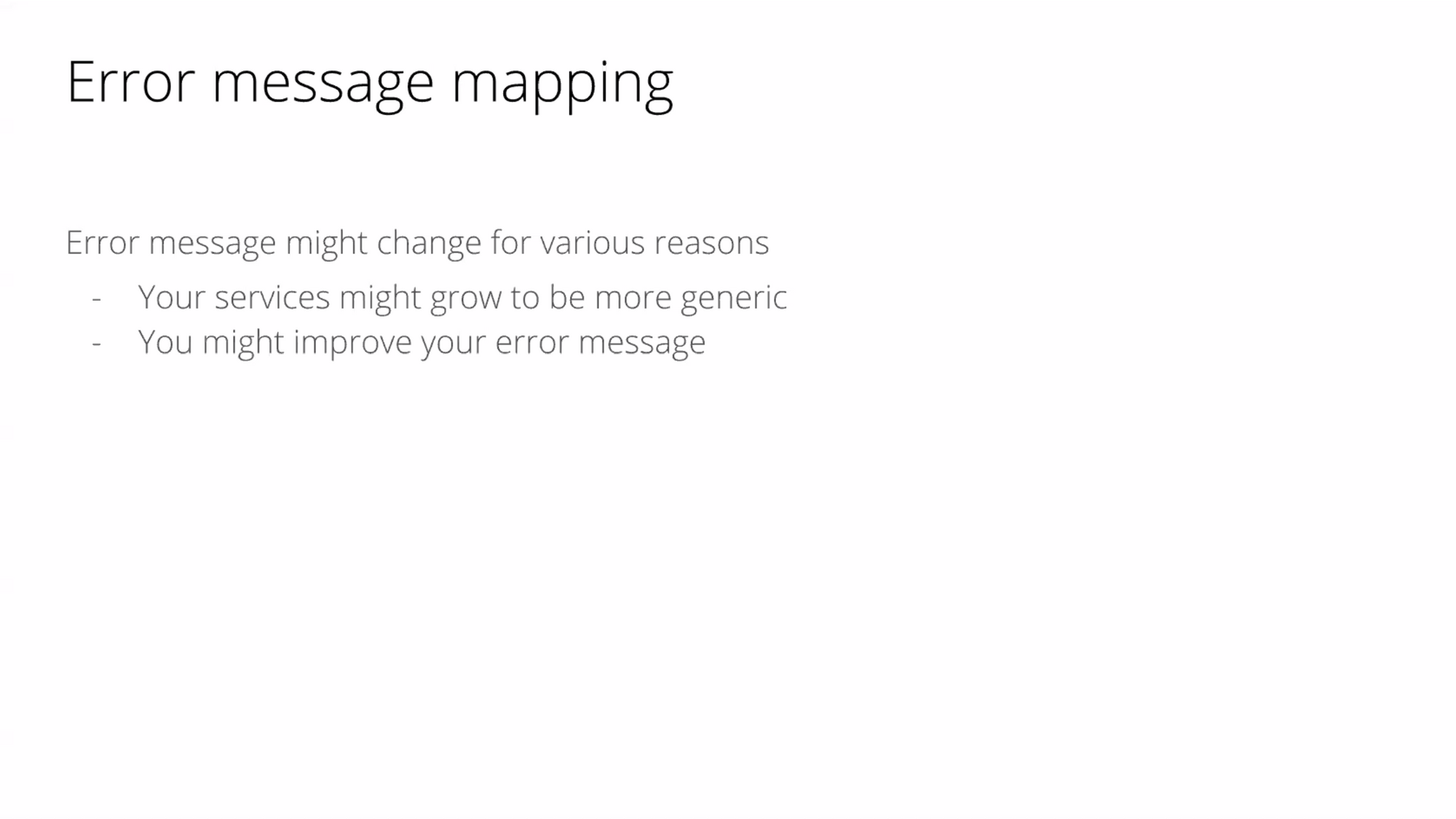
บางครั้งควรจะเริ่มจากอะไรที่เล็กๆก่อน แล้วค่อยเขียนโค้ดเอา message มา match กัน สิ่งที่เกิดขึ้นคือ ถ้ามีระบบที่ใหญ่ขึ้น และ support หลายๆช่องทาง จึงมีการเปลี่ยนแปลง message เกิดขึ้น แล้วมันไม่สามารถ match ได้เหมือนเดิม ทำให้มันพัง แล้วทีมอาจจะตีกันนิดนึงว่าใครต้องแก้ ซึ่งตัว Error Message นั้นถูกเปลี่ยนแปลงได้หลายเหตุผล ไม่ว่าจะเป็นเรื่อง generic type หรือแก้คำสะกิดผิดก็ตาม

ดังนั้น เราจะ match ผ่าน code แทน พอมีการเปลี่ยนแปลงก็จะไม่กระทบหล่ะ
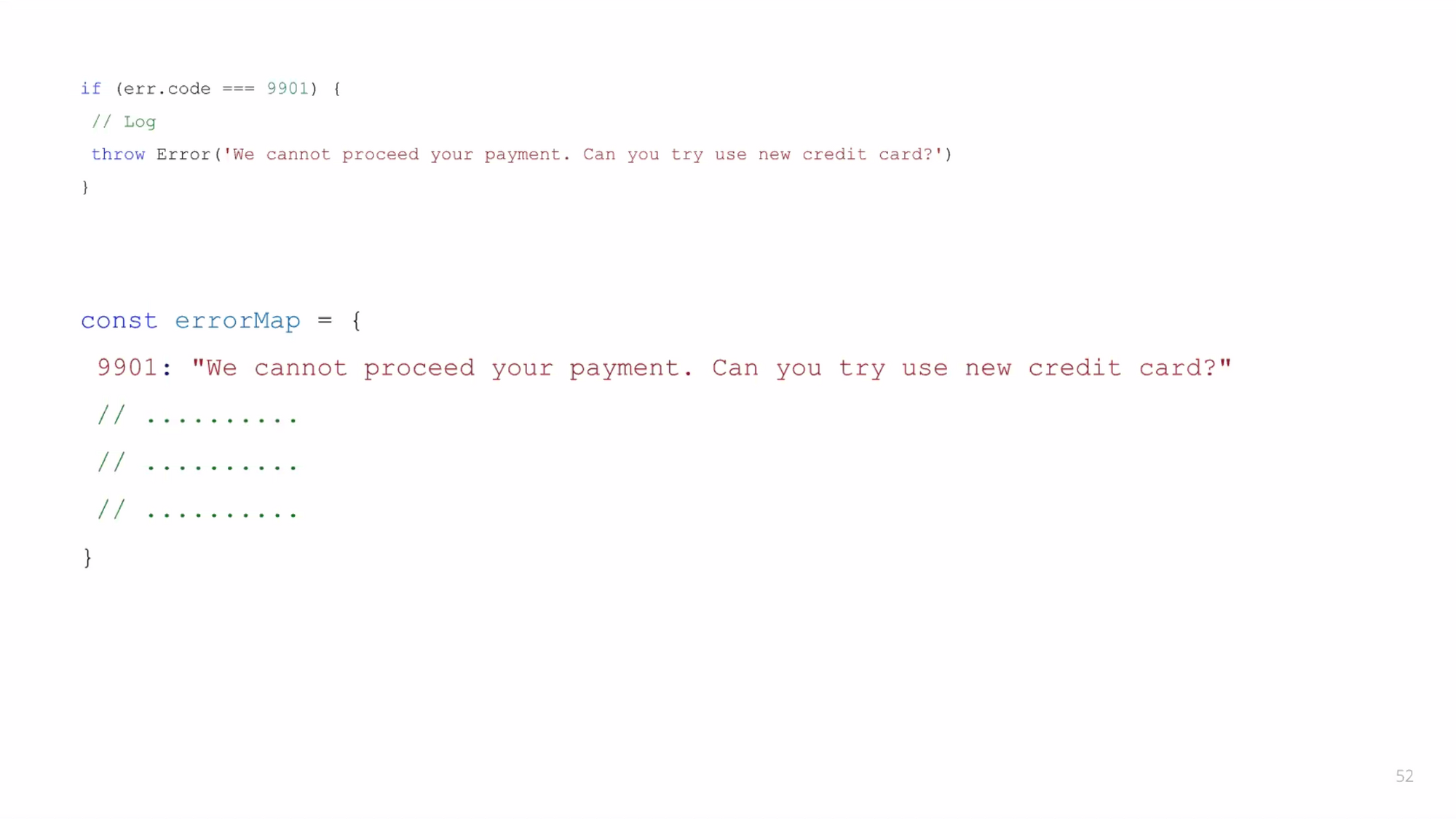
มีหลากหลายแนวทางให้ใช้
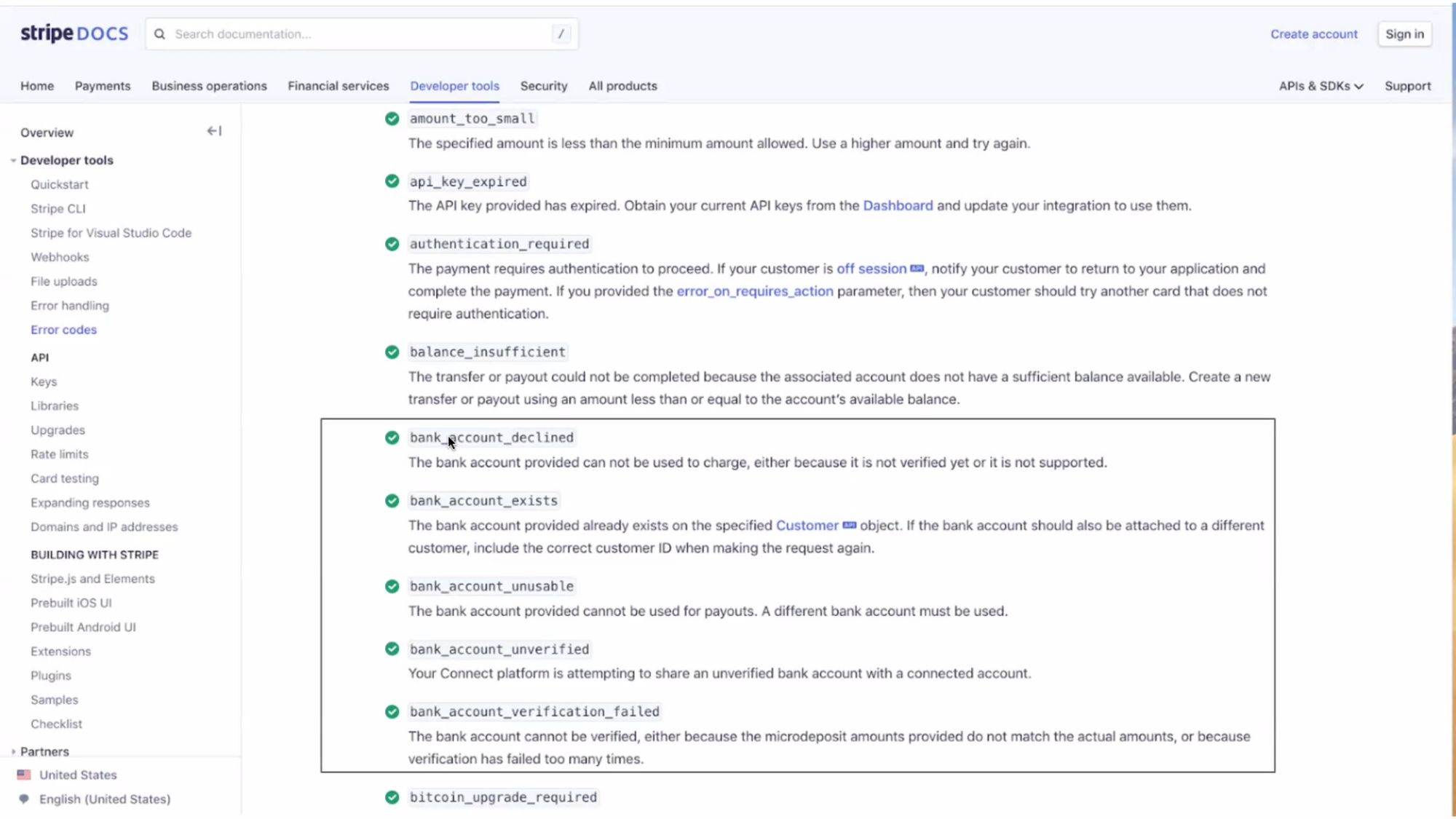
- มี http code มันจะเป๊ะ ไม่ต้องเปลี่ยนอะไร แต่ในทางเดียวกันก็ไม่ค่อยสื่ออะไร แต่บางทีก็พอจะเดาได้ จึงต้องมี document ควบคู่กันเสมอ
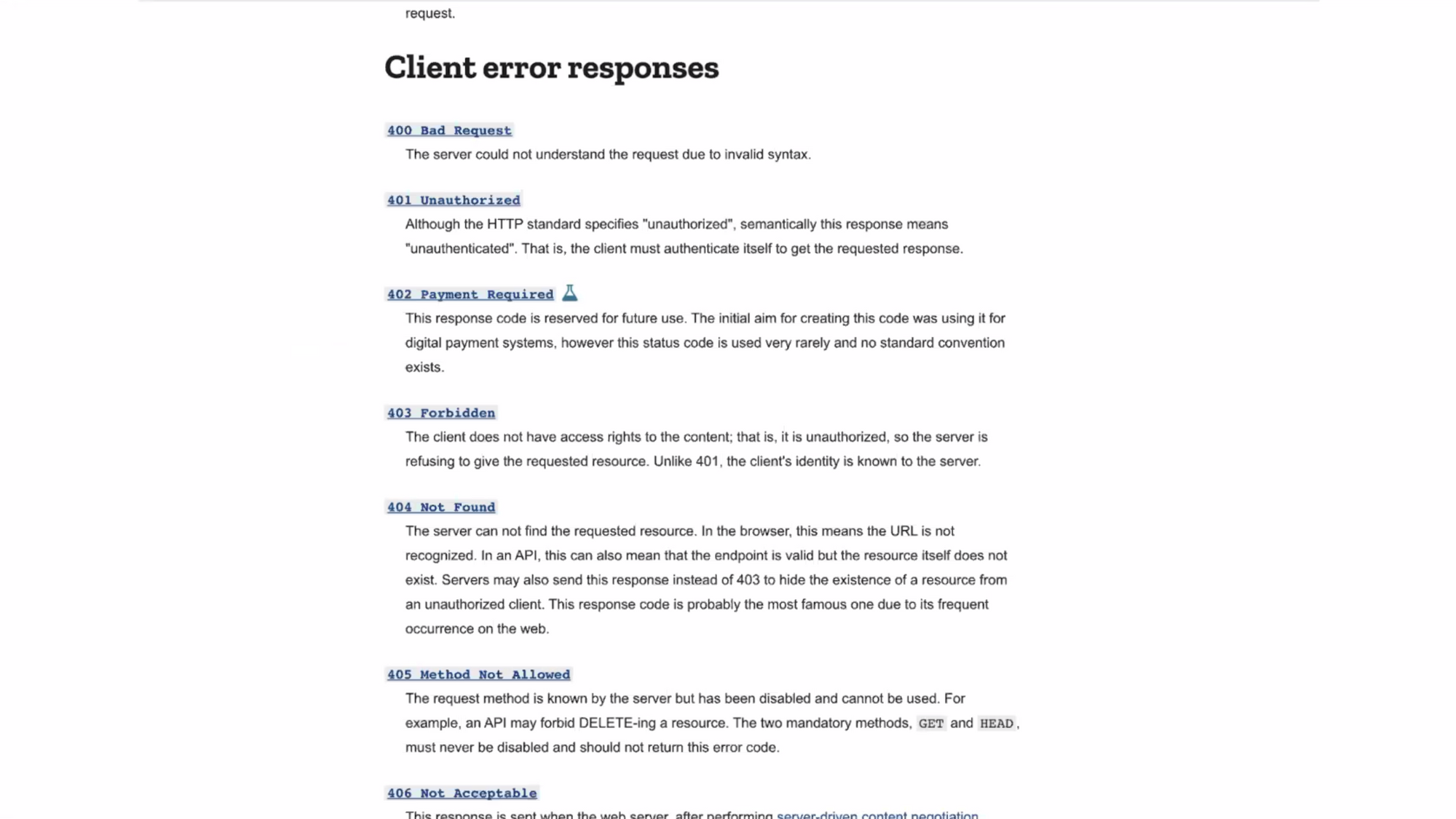
- มี mislead ได้ในการขยายระบบ เช่นใน slack api
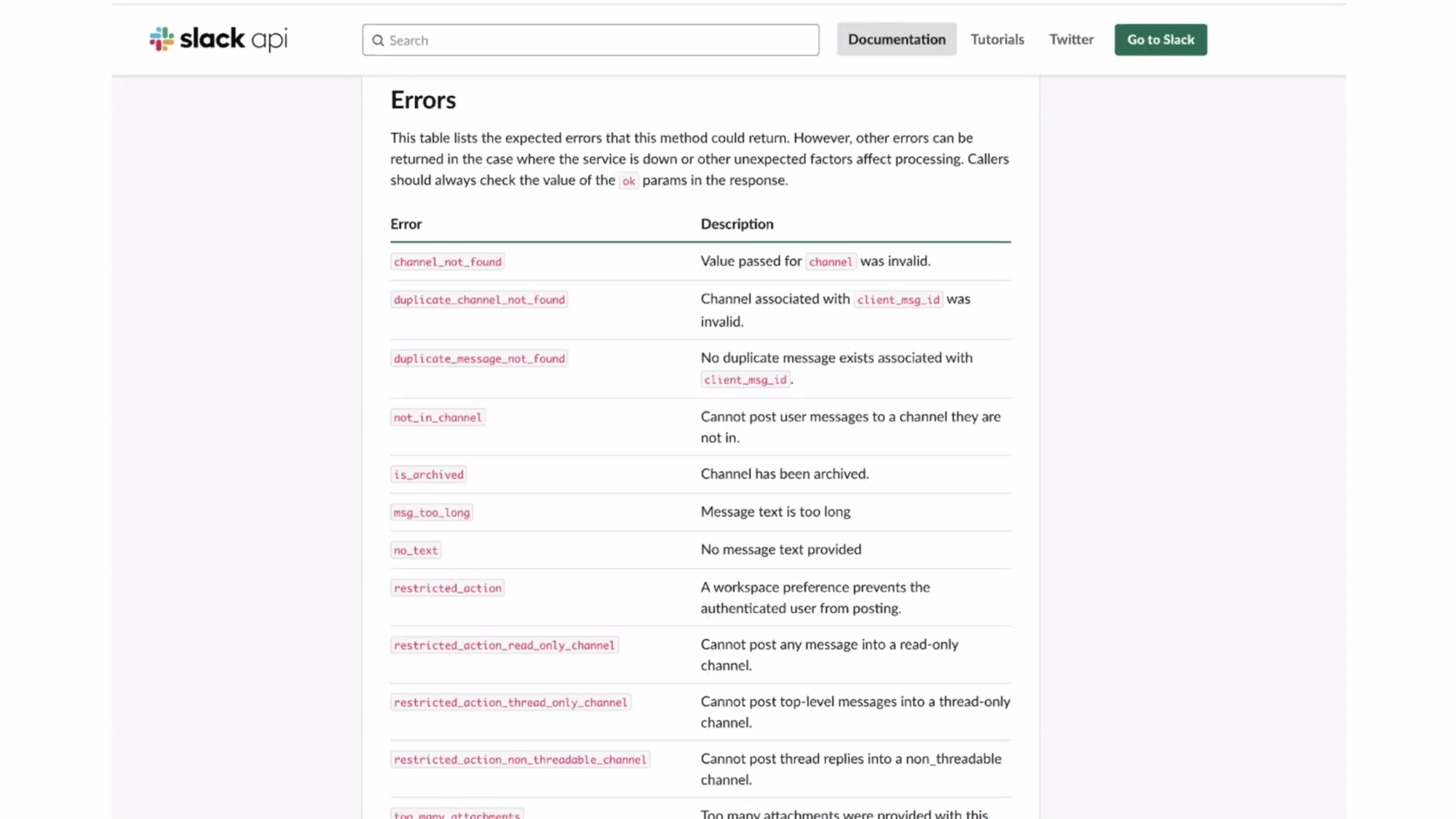
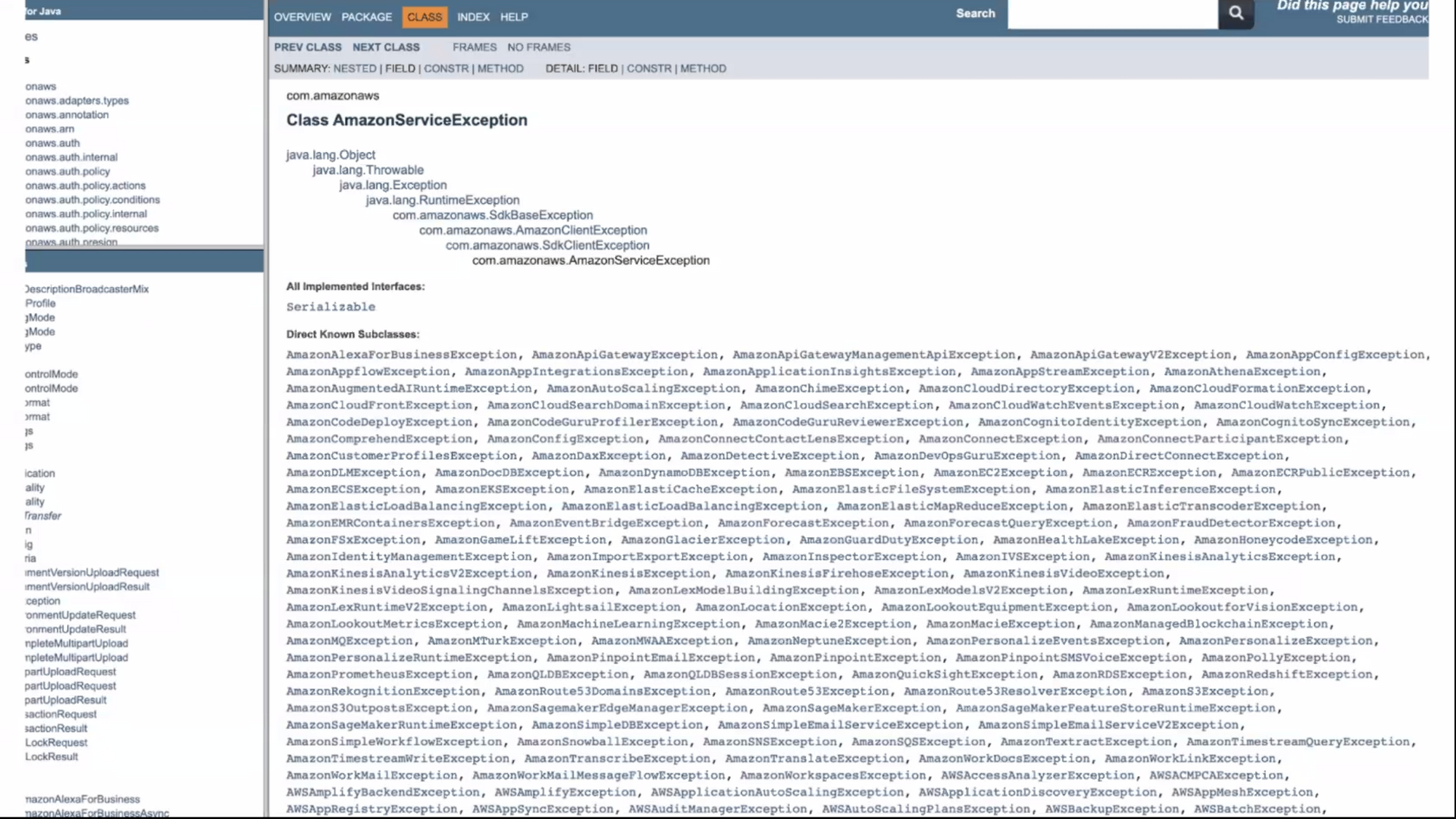
- ใช้ exception type ในการ identify เช่น ใน aws
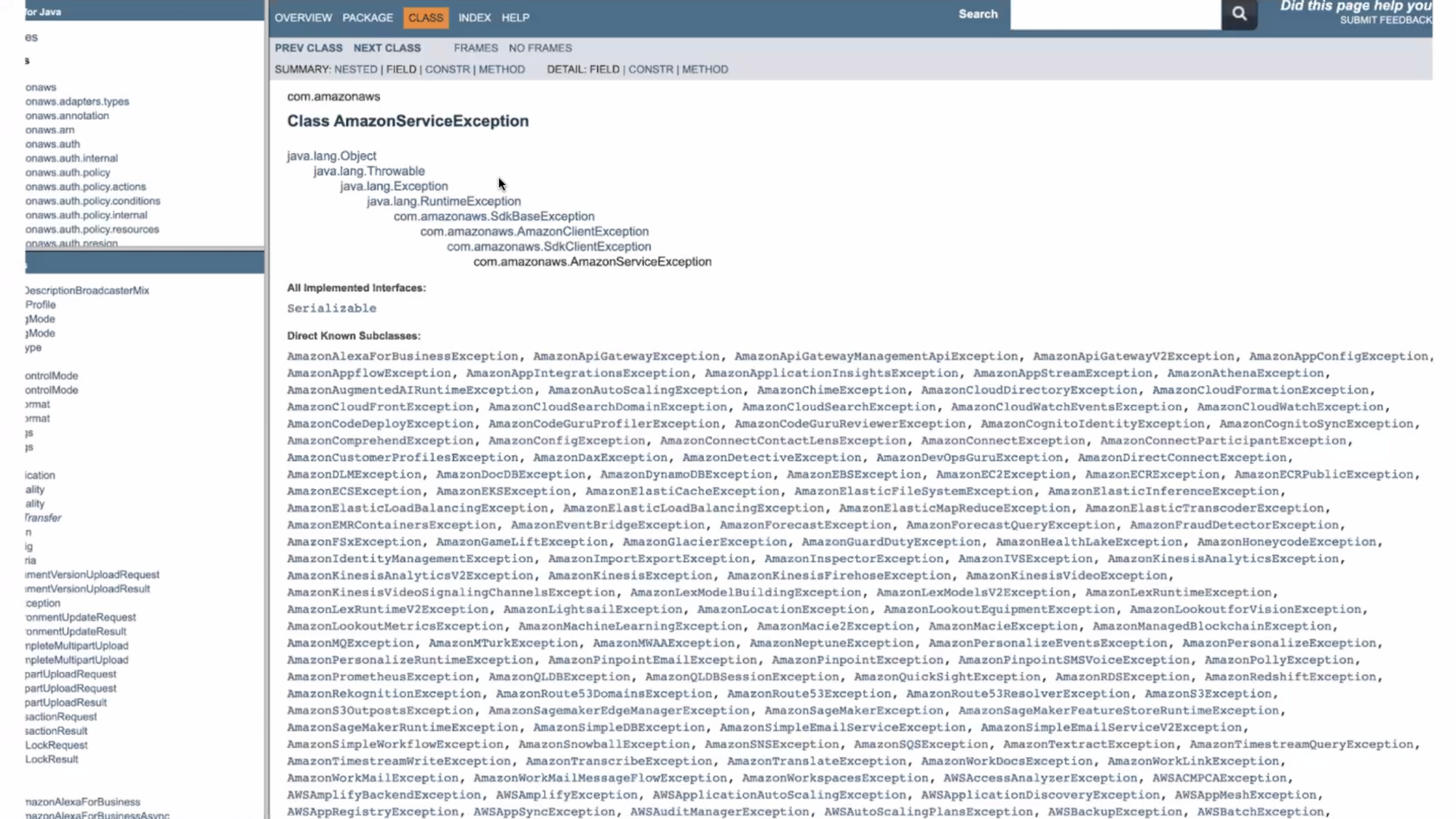
3) When unsure, be specific
เหตุการณ์สมมุติ(หรือเปล่านะ) เดฟหลังบ้านกำลัง handle error เคสนึง แต่ก็แบ่บนึกไม่ออกว่าใช้ exception อะไรดีนะ อาจจะเดินไปถามคนอื่น ทีมอื่น หรือไม่ก็ถามผู้ใหญ่คนนึงที่เป็นอากู๋
พอมาดูๆคำตอบก็ดู make sense นี่หน่า

วันเวลาผ่านไปก็จัดการอะไรเยอะขึ้น อ่ะเอาทุกอย่างมาใช้ด้วยกันเลยดีกว่า

วันดีคืนร้าย ฝ่ายบริการลูกค้าก็แล้วกัน (คือจำเป๊ะๆไม่ได้แต่น่าจะแบบนี้แหละ คุยกับลูกค้างาย) มาถามทีมระบบว่า เอ้ออ มีเคสตัดเงินไม่ได้เพราะใส่ยอดเงินไม่ถึง 100 บาทเท่าไหร่ค่ะ เอาล้าววว เลิ่กลั่ก เนื่องจากมันเริ่ม tracking ยาก เพราะเอามันมาไว้ด้วยกันหมดเลยอ่ะ ก็เลยไม่สามารถจัดการหาข้อมูลที่ต้องการได้

แล้วมันก็จะมูฟออนเป็นวงกลม กลับไปใช้ text แบบเดิมแทน...

จากเหตุการณ์ที่เกิดขึ้น มันผิดมาจากตรงไหน คำตอบ ก็คือ ตอนที่คิดไม่ออกแล้วไปถามคนอื่นๆว่าเขาใช้กันยังไงนี่แหละ

ดังนั้น ถ้าไม่แน่ใจว่าใช้ error อะไร ให้ใช้ที่ specific ที่สุดที่เป็นไปได้ ไม่จำเป็นต้องยาว เอาที่มันเฉพาะเจาะจง
การจัดการ Error Type
- ให้ introduce error ใหม่ เพื่อไม่ให้รู้สึกกลัวการสร้าง new error type จนเกินไปจนไม่กล้าจะทำอะไร
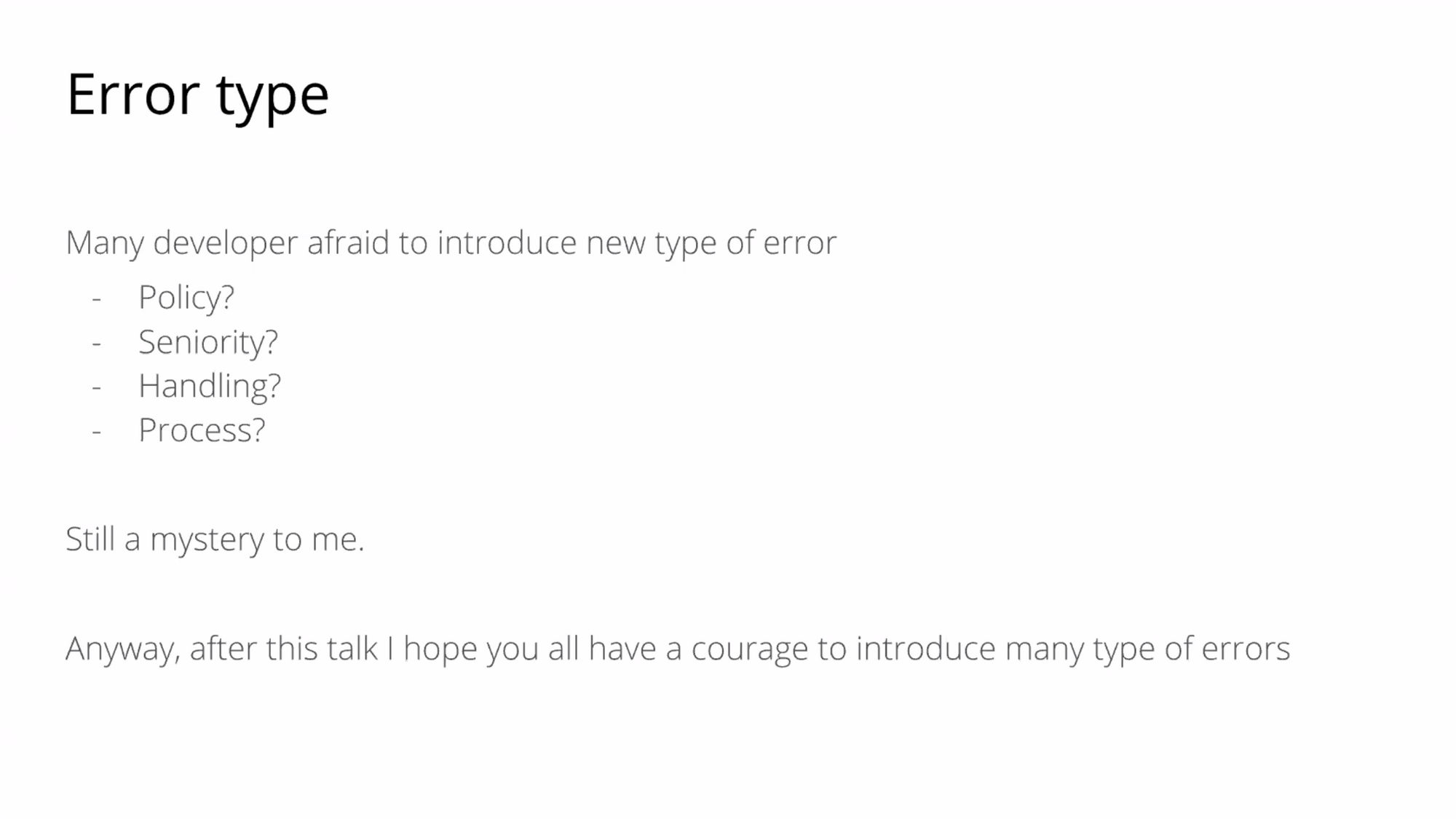
- เมื่อไหร่ที่มันจะ error หาลองหาสาเหตุของมันก่อน มันจะง่ายต่อการ generate error มากกว่าจะระบุ error ไปเลย
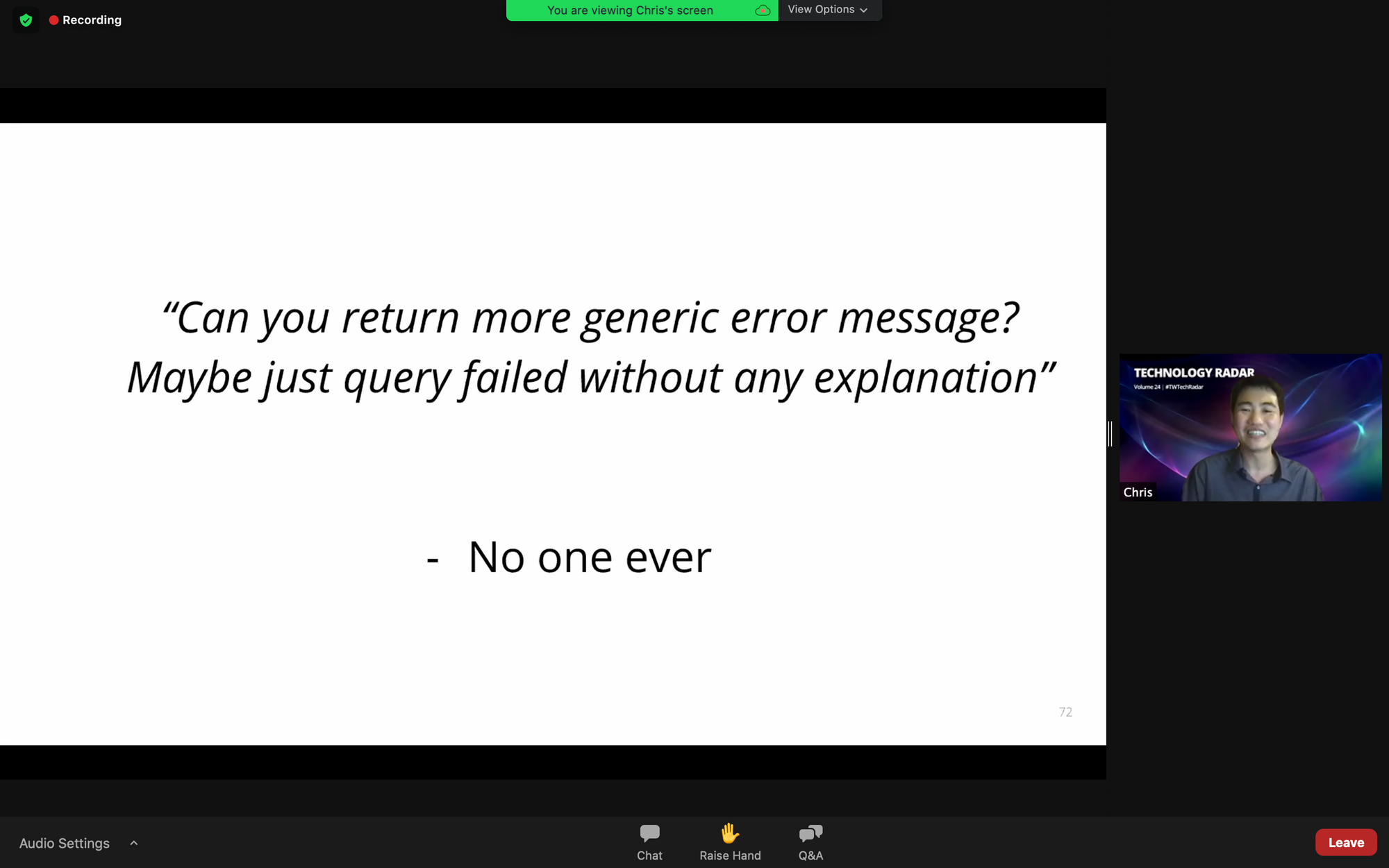
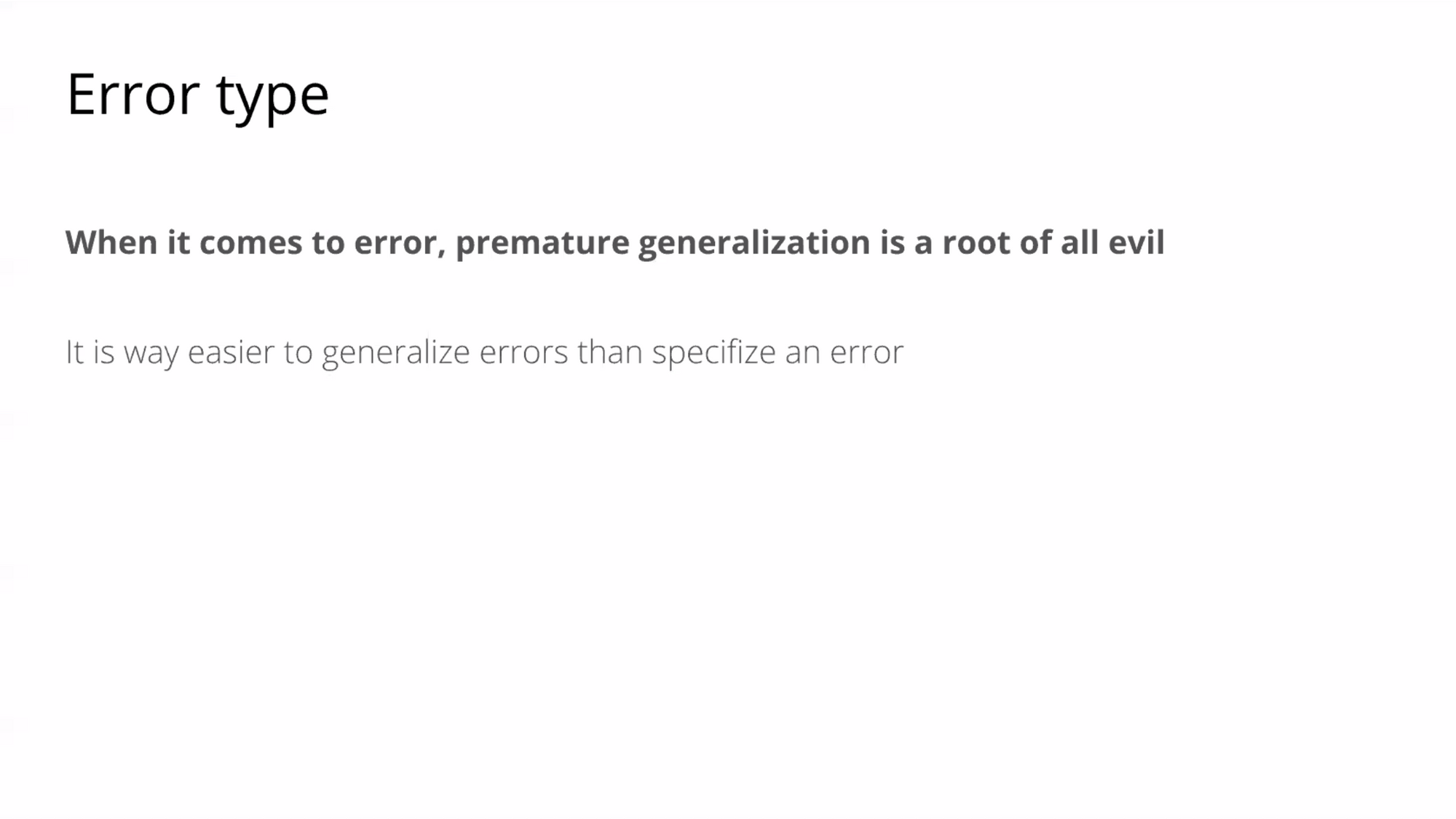
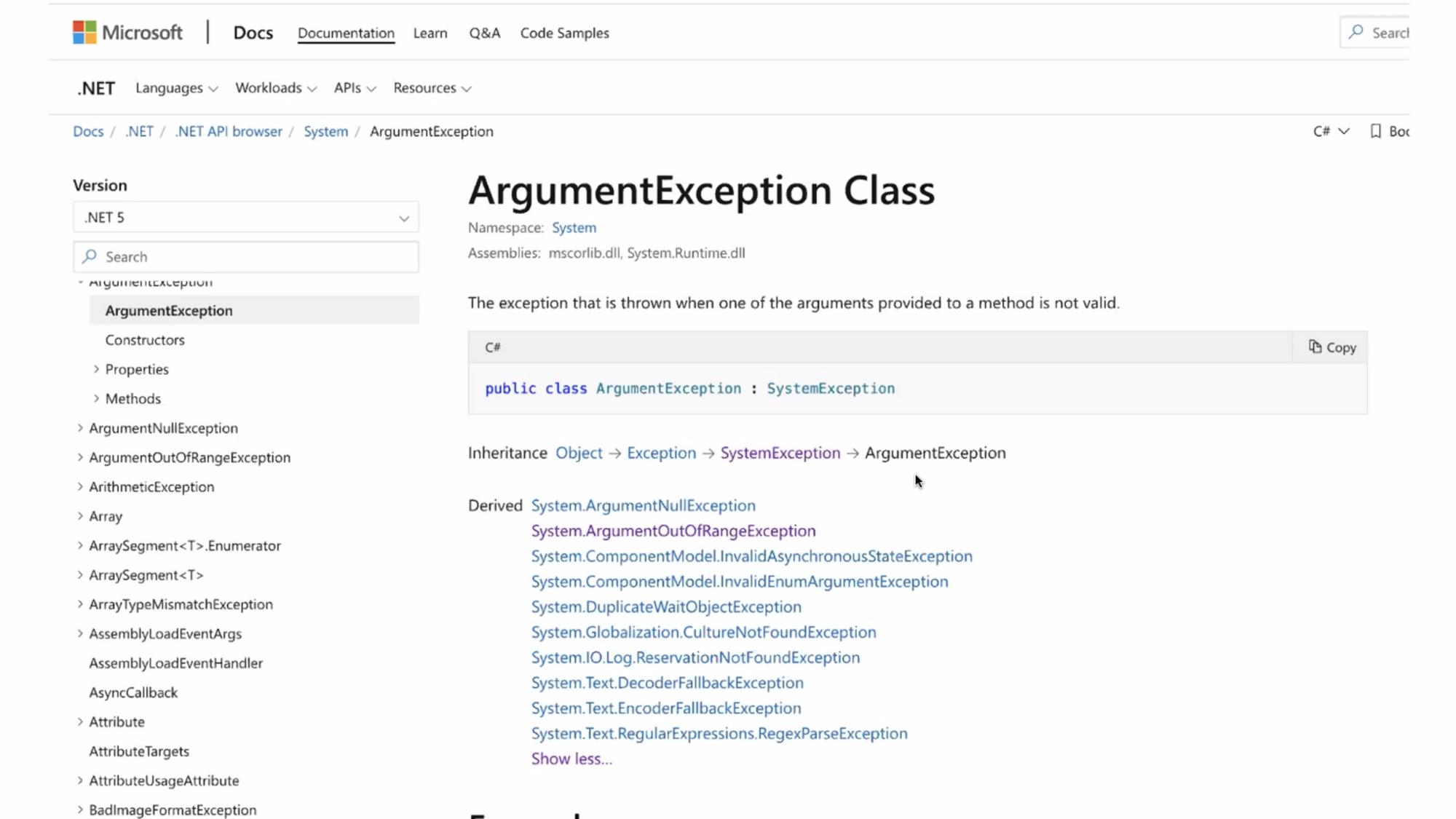
- เริ่มจากแบบ specific ก่อน แล้วค่อยไปจัดกลุ่มมันอีกที เช่น ใน aws


4) Categorized your error
สมมุติเรามี Error Type 5 ตัว เราควรจัดกลุ่ม Error ของเราเสมอ
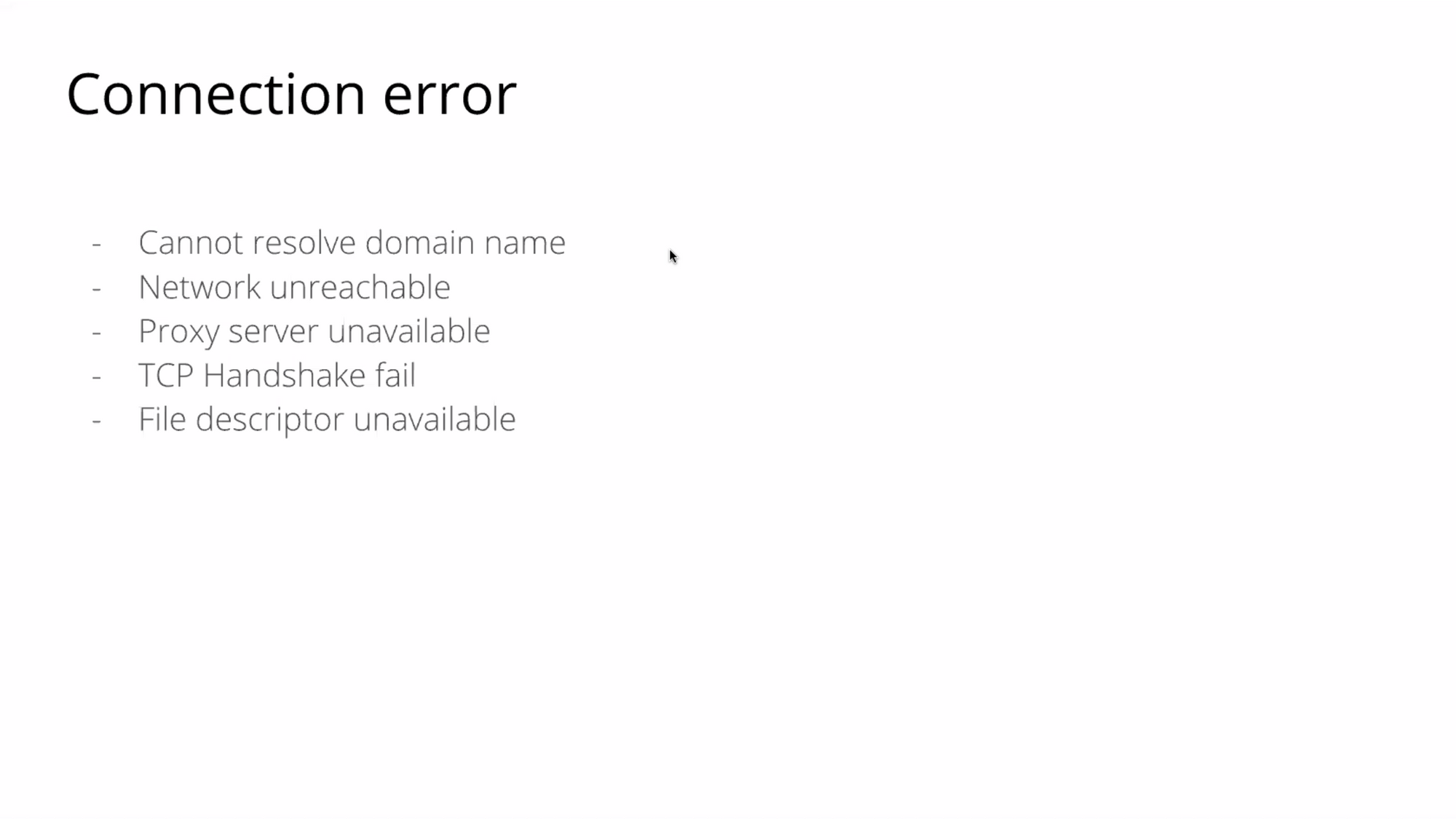


วิธีการจัด category ของมันก็จะมีหลายแบบเลย เช่น จัดด้วย prefix อาจจะเป็นแบบ HTTP Code

หรือนำด้วย error type เป็น prefix แบบนี้

และมี hieracy ในการจัดกลุ่มซ้อนกลุ่ม ทำให้สามารถแยกออกได้ง่าย
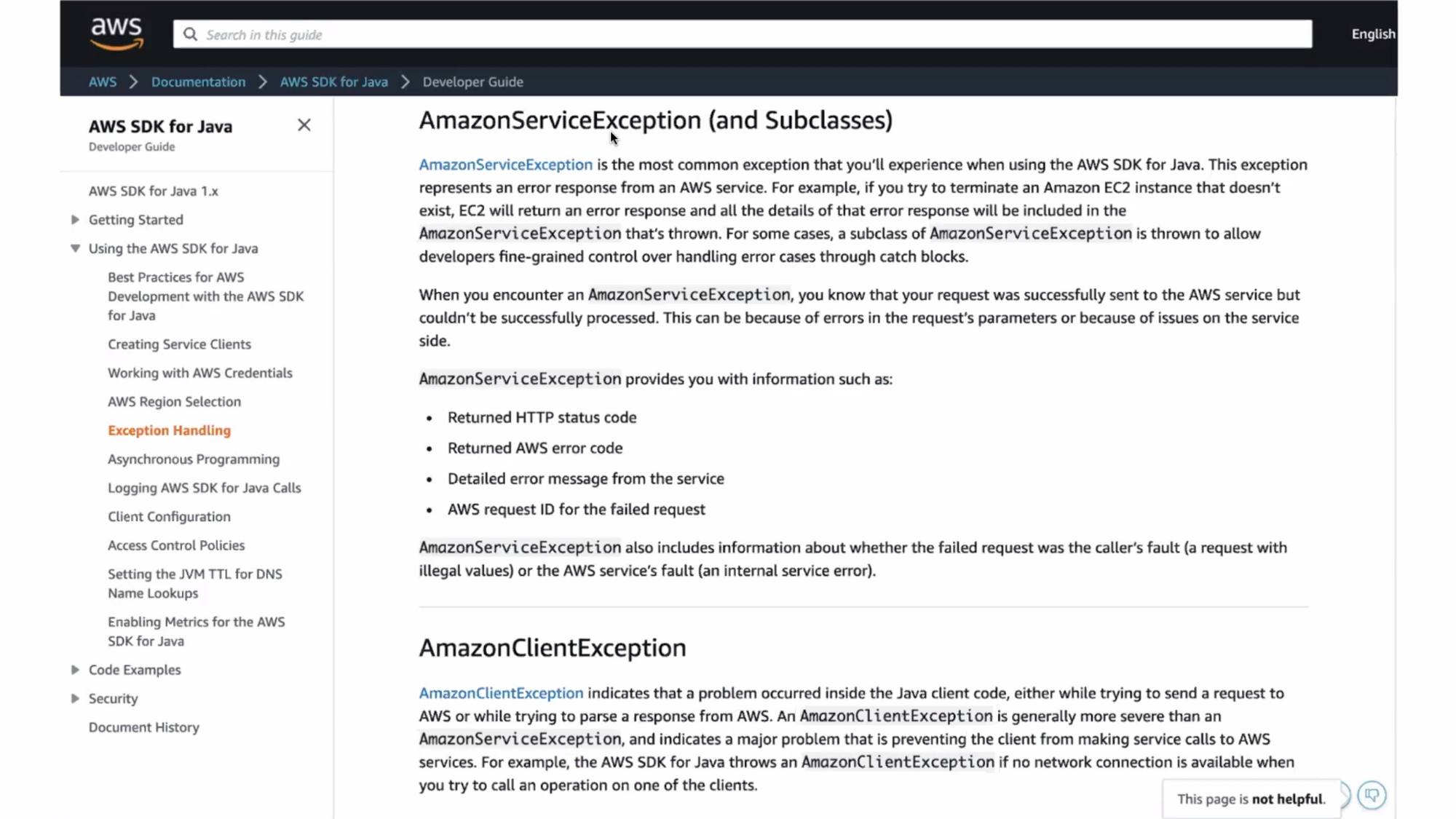
5) Have distributed tracing
ถ้า service payment ลูกค่าจ่ายเงินไม่ได้ เราจะทำยังไงดีหล่ะ?
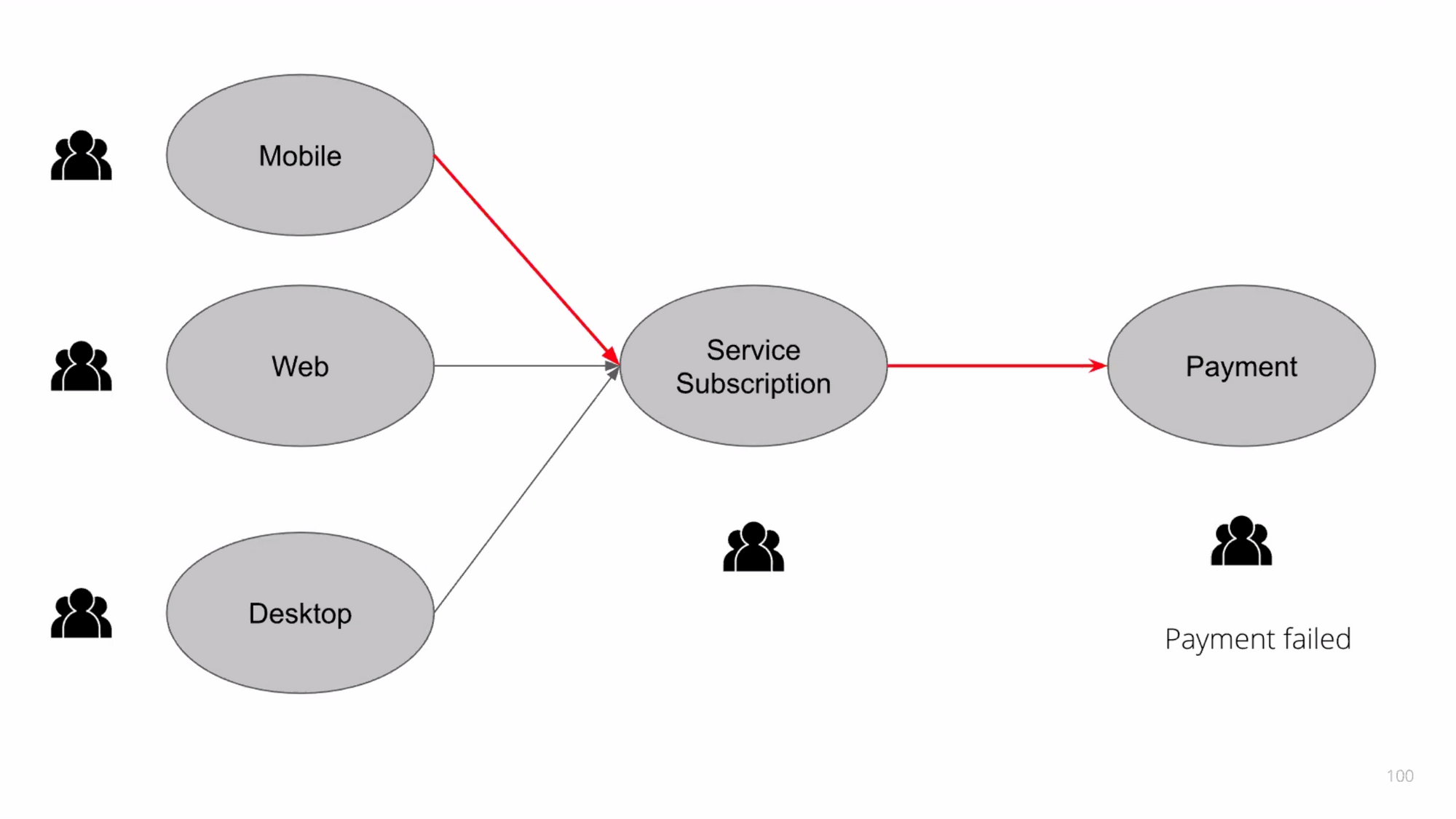
พอเจอว่ามีส่ง argument ผิด แล้วดันหาไม่เจอว่าใครเป็นคนส่ง ซึ่งมันไม่ work เนอะ
Distributed Tracing เป็น tool ที่สามารถบอกได้ว่า จากต้นนํ้าไปปลายนํ้า เกิดอะไรขึ้นบ้าง ไปเรียกอะไรตอนไหน ใช้เวลาเท่าไหร้ พังตรงไหน ทำให้สามารถดูได้ว่าปัญหาเกิดจากตรงไหน และสามารถทำ end-to-end operation ได้ มี tool ต่างๆให้ใช้
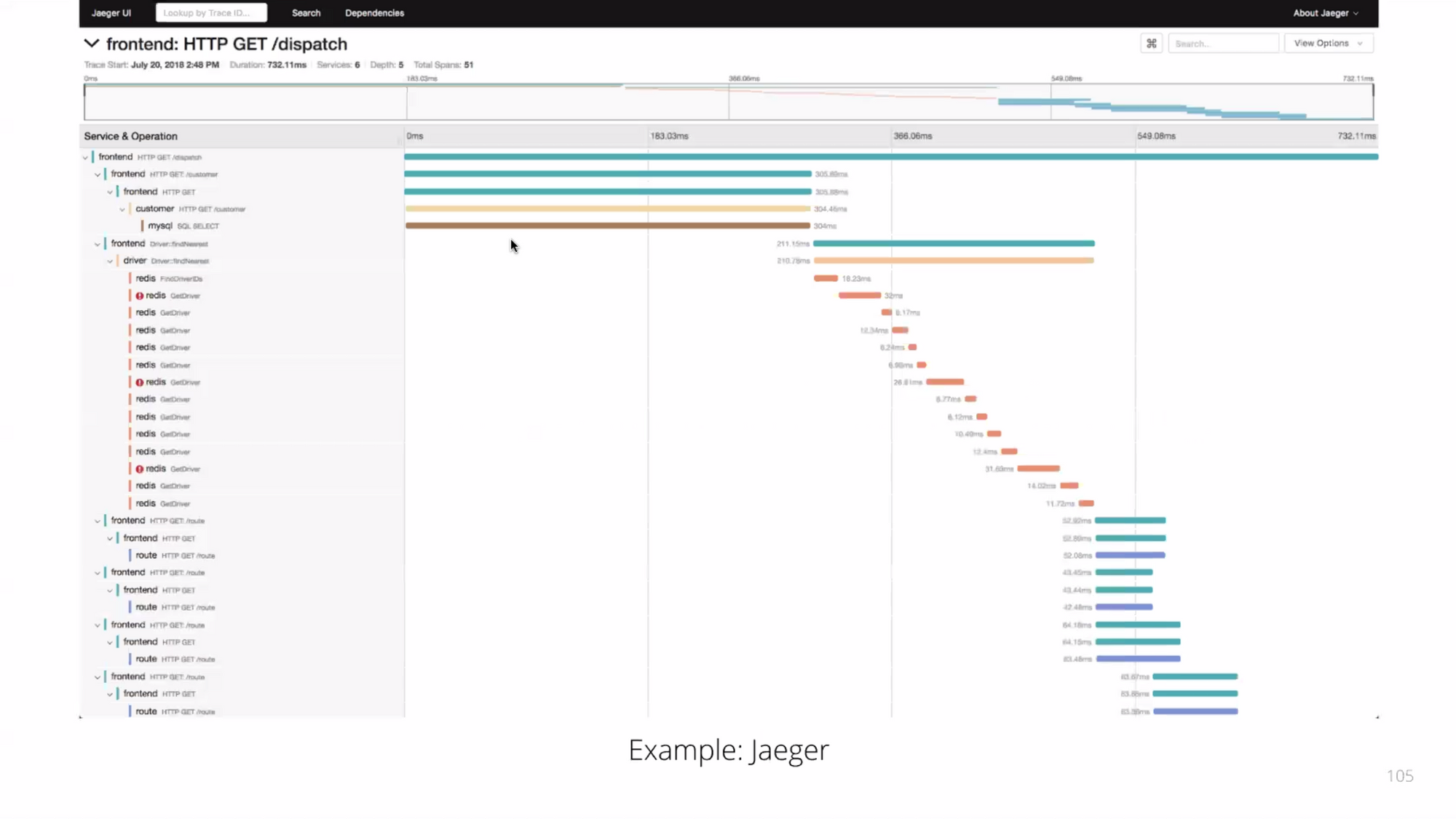
วิธีการคือ ส่งข้อมูลไปยัง server (ตรง protocol) และเลือก visualization tool มารับและแสดงผล

Wrap-up
ประเด็นที่น่าสนใจเกี่ยวกับ Managing Error Message 5 ข้อที่นำไปปรับใช้ได้

- ดูแล customer ของตัวเอง ไม่ใช้ downstream จัดการ
- มี code รองรับเสมอ
- ถ้าไม่แน่ใจ ให้สร้าง error ใหม่ซะ
- จับกลุ่ม error
- ใช้ tracing tool
สุดท้าย

ช่วง Q & A อยากให้ฟังเองมากกว่าง่ะ เพราะพี่ speaker เขาน่าจะเป็นสายทำพวกระบบหลังบ้าน เราฝั่งหน้าบ้านอาจจะไม่เก็ททุกคำพูดของเขา แหะๆ
อันนี้ทาง ThoughtWorks ฝากร้าน เลยแปะทุกลิ้งในช่องแชทตรงนี้เลยแล้วกัน
Technology Radar: https://thght.works/3dQBRcl
XConf Southeast Asia: https://thght.works/2QDboGl
ตำแหน่งงานที่เปิดรับ: https://thght.works/2XQWtZm
สมัครรับจดหมายข่าว: http://thght.works/3szdN2W
Feedback Form: https://forms.gle/Lw27sbj2ETd36D6e8
Meetup Group: https://www.meetup.com/thoughtworks-thailand-meetup-group/
ThoughtWorks Talks Tech Facebook Group: https://www.facebook.com/groups/2526438034093963/
ในส่วน Technology Radar ฉบับที่ 24 เนี่ย ใน podcast LINE Developers Podcast ตอนล่าสุดเลยนะ
download แอพอ่านบล็อกใหม่ของเราได้ที่นี่

ติดตามข่าวสารและบทความใหม่ๆได้ที่
อย่าลืมกด like กด share บทความกันด้วยนะคะ :)
Posted by MikkiPastel on Sunday, 10 December 2017
ช่องทางใหม่ใน Twiter จ้า
สวัสดีจ้า ฝากเนื้อฝากตัวกับชาวทวิตเตอร์ด้วยน้าา
— mikkipastel (@mikkipastel) August 24, 2020
และ YouTube ช่องใหม่จ้า