ทำความรู้จัก Regular Expression แบบ 101 กัน
developer น่าจะเคยเห็น RegEx ผ่านตา และเคยเอามาใช้งานกันมาบ้าง
สำหรับคนทั่วไปอาจจะไม่รู้จักว่า RegEx คืออะไร? แล้วเดฟเอาไปใช้ทำอะไร?
แล้วมันคืออะไรล่ะ? เราสรุปจากที่เราเรียนจาก “Google IT Automation with Python Professional Certificate” ซึ่งเรื่อง RegEx อยู่ใน module 3 ของบทเรียนย่อย “Using Python to Interact with the Operating System” แน่นอนว่าต้องใช้ Python เนอะ

แล้ว RegEx คืออะไร? มีไว้ทำไม? ใช้อะไรบ้าง? มาอ่านกัน
RegEx คืออะไร?
RegEx หรือ Regular Expressions เป็นเครื่องมือที่ใช้ในการค้นหา, จัดการข้อความตาม pattern ที่เราต้องการ และเพื่อ validate บางอย่าง
RegEx ถูกใช้ทำอะไรบ้าง?
- Searching: เอาไว้ค้นหาคำตาม pattern ที่เราต้องการ
- Matching: เอาไว้ matching เพื่อ validate user input เช่น คนนี้ใส่ email ตรง format ไหม
- Replacing: ใช้ค้นหา และเปลี่ยน text ตาม pattern เช่น เปลี่ยนหลาย ๆ space ให้เหลือ space เดียว
- Extracting: ใช้ extract information บางอย่างออกจาก text เช่น วันที่ เบอร์โทร email
- Splitting: ใช้ตัดคำ อันนี้เหมาะกับการใช้กับ log file หรือพวก csv
🖍️ มีแล้วชีวิตเปลี่ยนยังไง?
สมมุติว่าเราค้นหา process id (PID) จาก log นี้
log = “July 31 07:51:48 mycomputer bad_process[12345]: ERROR Performing package upgrade”
ซึ่งก็คือ 12345 เนอะ
วิธีการได้มาคือ เราก็นับว่า วงเล็บใหญ่เปิดอยู่ตรงไหน แล้วก็นับไปอีก 5 ตัวอักษร ก็จะได้ล่ะ
index = log.index(”[”)
log[index+1:index+6]
แต่ถ้าค่า log เปลี่ยน แล้วตำแหน่ง square bracket ขยับ แล้วถ้า process id ยาวขึ้นหรือสั้นลงล่ะ เท่ากับไม่สามารถใช้ได้ทุกเคสถูกม่ะ?
แต่เรารู้อยู่แล้วว่า pattern มันคืออะไร? process id จะอยู่ใน square bracket ถูกม่ะ?
ดังนั้นจึงต้องใช้ RegEx ในการเอาค่า process id ออกมา
import re
log = “July 31 07:51:48 mycomputer bad_process[12345]: ERROR Performing package upgrade”
regex = r"\\[(\\d+)\\]"
result = re.search(regex, log)
print(result[1])
🖍️ Basic Matching with grep
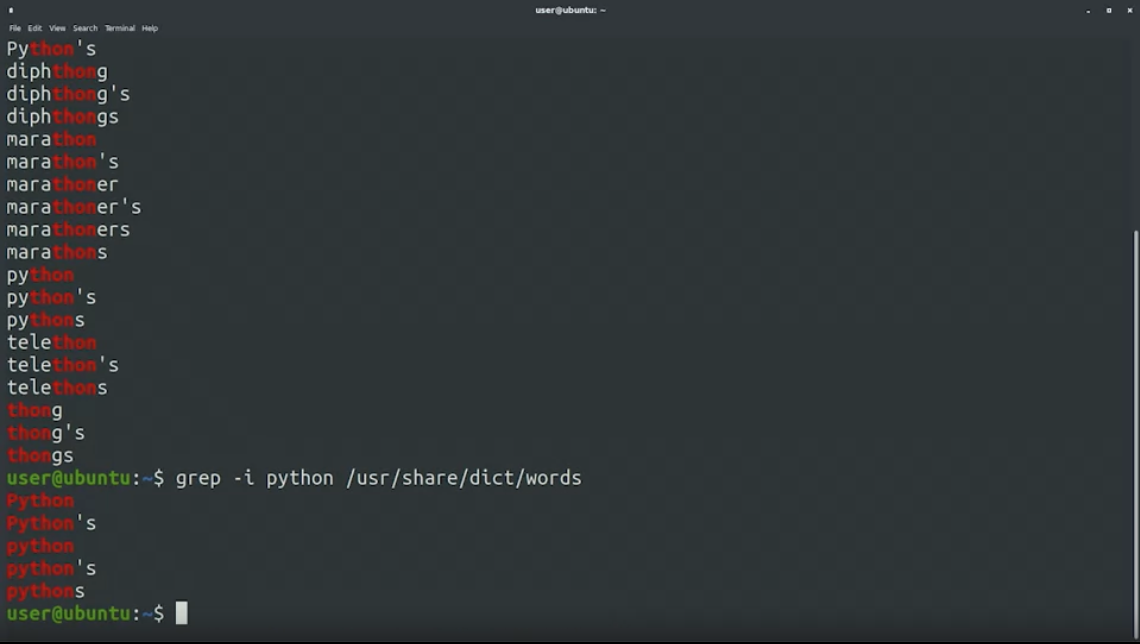
grep เป็น command-line RegEx tool ที่ง่ายและทรงพลังสุด ๆ ในการนำ RegEx ไปใช้ เช่นเราอยาก search คำที่มีคำว่า “thon” สามารถพิมพ์ command grep thon /usr/share/dict/wordsผลจะเป็นแบบนี้ ดึงคำที่มี “thon” ออกมาให้เรา พร้อม highlight สีแดง ๆ ให้ด้วย
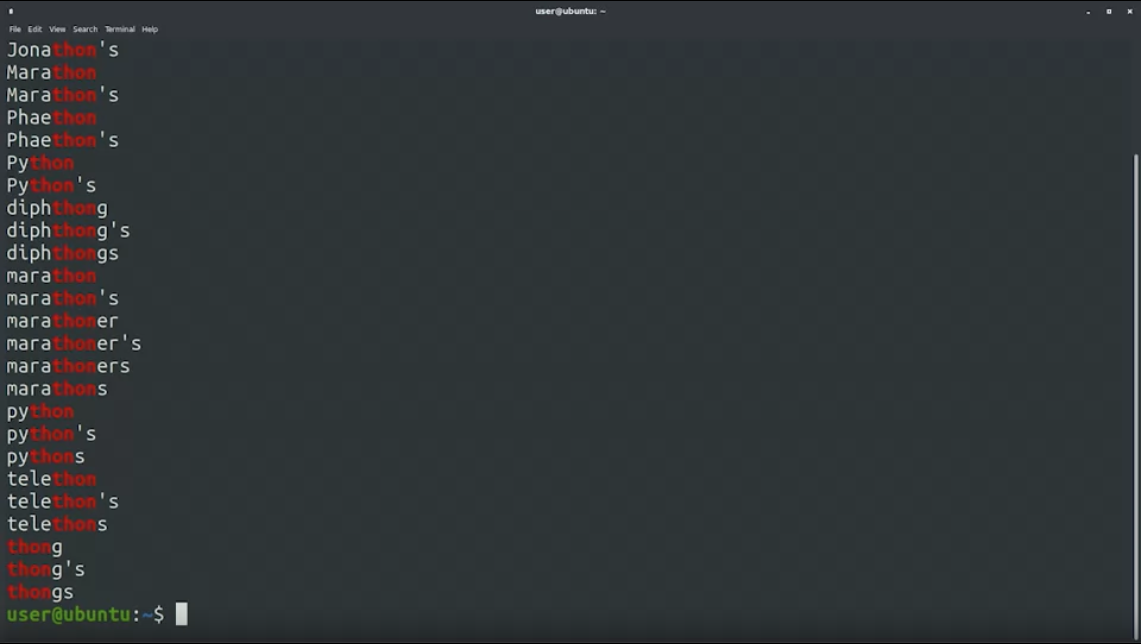
ถ้าอยากได้คำว่า “python” โดยไม่สนตัวเล็กใหญ่ ใส่ -i ลงไป พิมพ์ grep -i python /usr/share/dict/words
มาเรียนรู้ syntax อื่น ๆ เกี่ยวกับ RegEx กัน เรียกว่า Reserved Characters
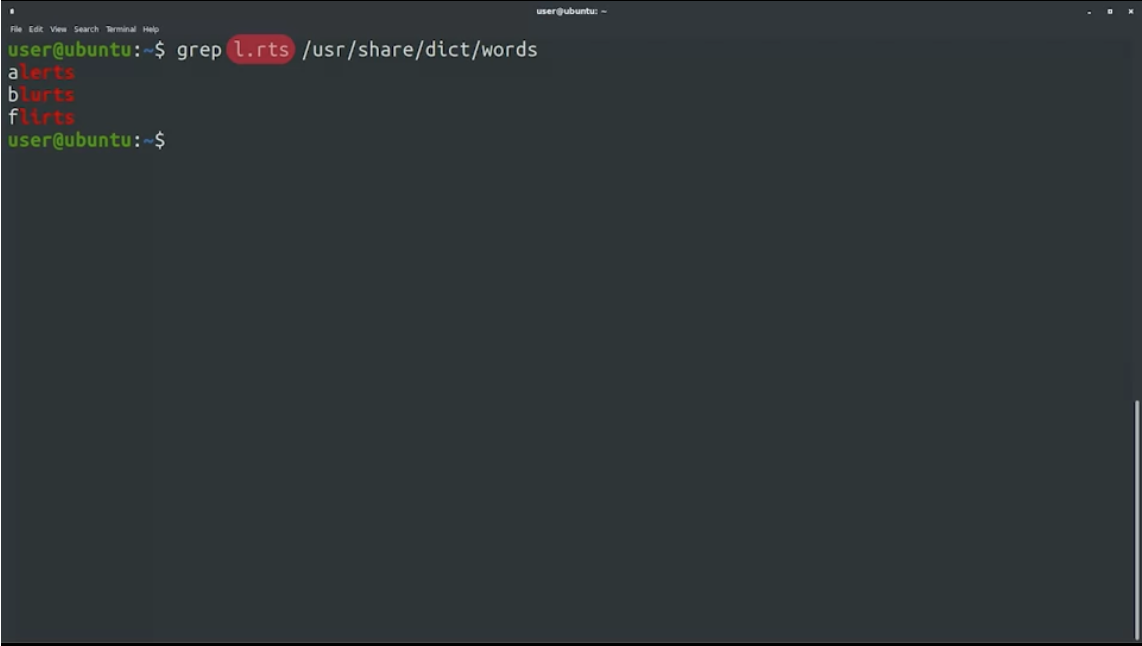
.เป็น wildcard ที่สามารถแทนที่แต่ละ character ใน result ได้ เช่นgrep l.rts /usr/share/dict/wordsจะได้คำที่มี l ข้างหน้า ตามด้วยอะไรสักตัว แล้วจบด้วย rts
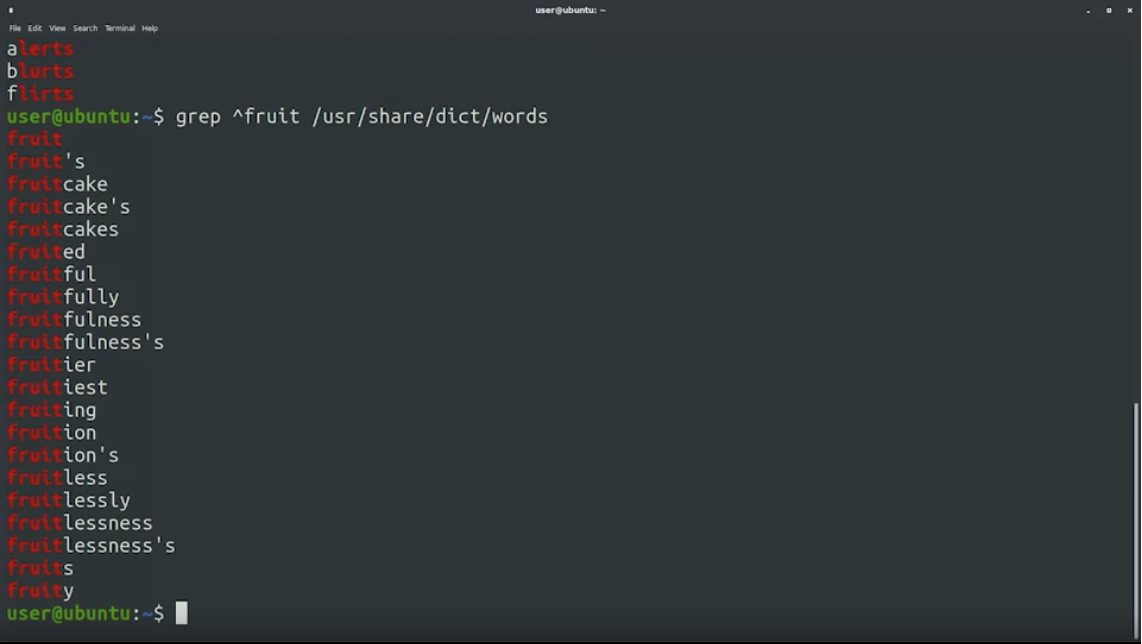
^นำหน้าที่ string เราต้องการ เช่น ต้องการคำที่นำหน้าว่า fruit มันจะ match ให้ตามนี้
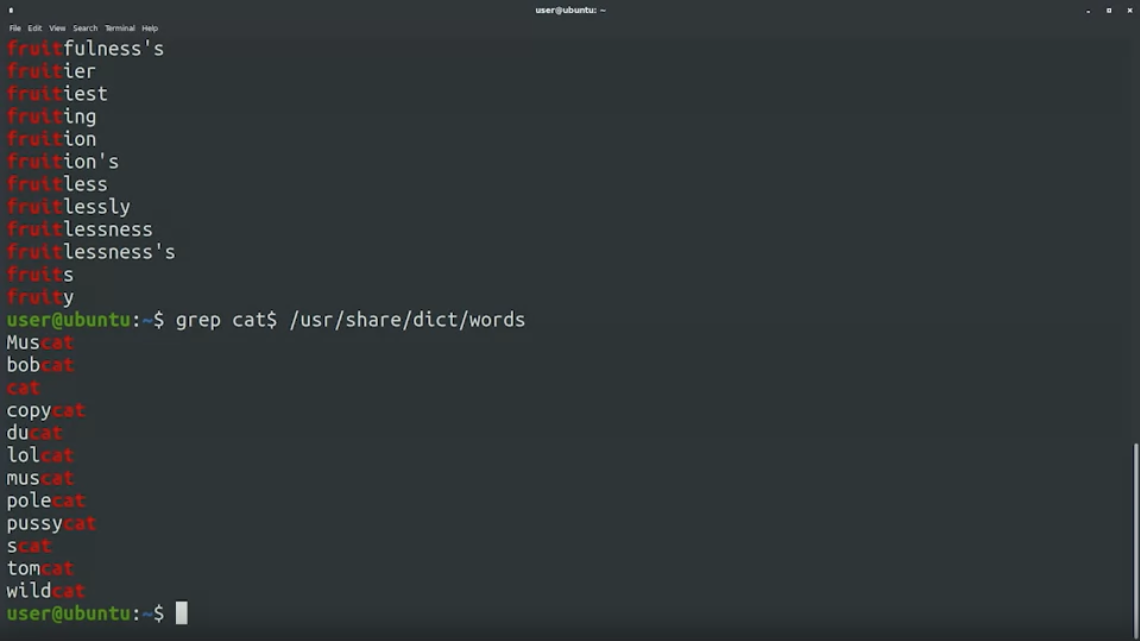
$ลงท้าย string ที่เราต้องการ เช่น ต้องการคำที่ลงท้ายว่า cat มันจะ match ให้ตามนี้
Basic Regular Expressions
🖍️ Simple Matching in Python
เริ่มลง code ภาษา Python ล่ะ ใช้ re.search() เพื่อหาคำที่ match กับ pattern
ผลลัพธ์มี 2 แบบ คือ
- match: return ออกมาเป็น object ว่ามัน match ตรงไหน แล้ว match ด้วยอะไร
- not match: return None ออกมา หมายความว่าไม่มีค่าจากผลลัพธ์อันนี้
r เป็น raw string ใช้เพื่อหลีกเลี่ยงปัญหาที่เกี่ยวกับ special characters สำหรับการทำ RegEx บน Python จึงใส่ไว้ด้านหน้า "
import re
# match: return object
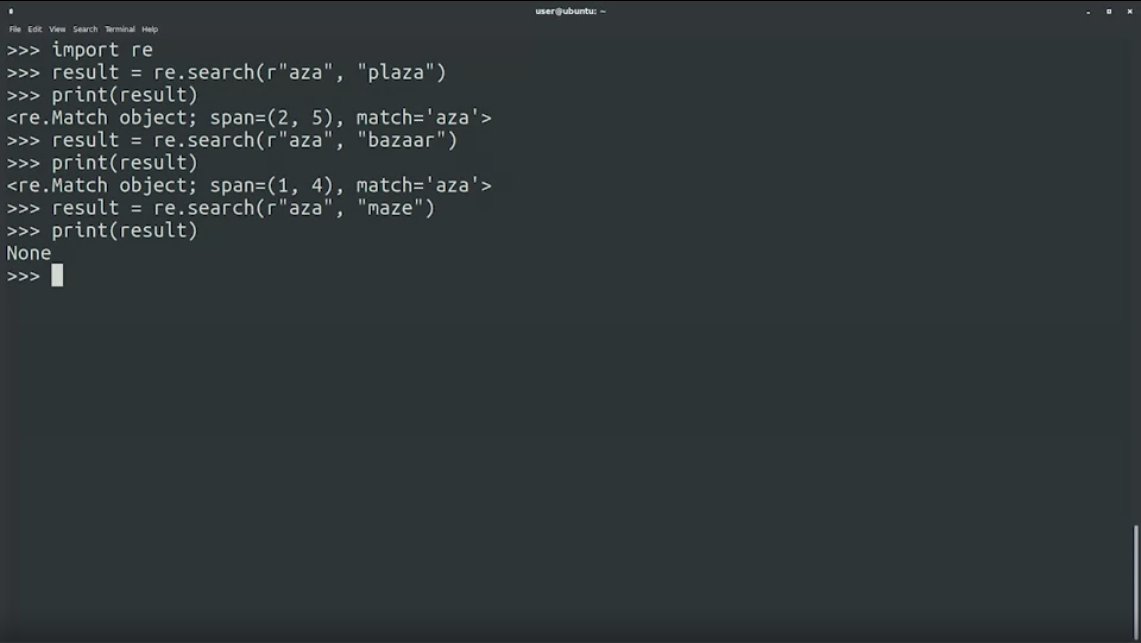
result = re.search(r"aza", "pizza")
result = re.search(r"aza", "bazaar")
# not match: return None
result = re.search(r"aza", "maze")
ลอง applied กับ Reserved Characters ที่เรียนมาเมื่อกี้
import re
print(re.search(r"^x", "xenon")
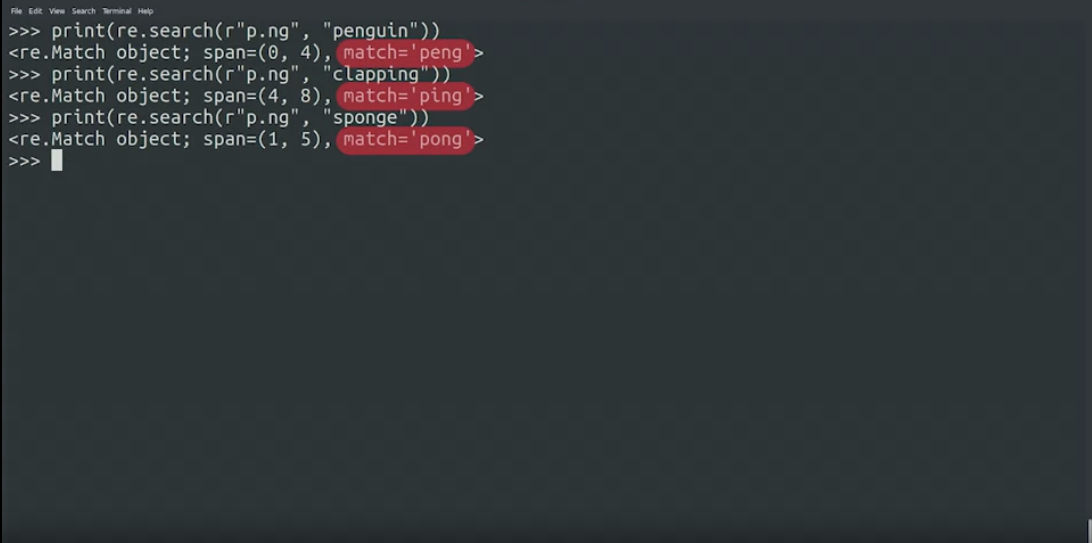
print(re.search(r"p.ng", "penguin")
print(re.search(r"p.ng", "clapping")
print(re.search(r"p.ng", "clapping")
print(re.search(r"p.ng", "sponge")
เราสามารถ modify search behavior กับ re.search() ได้ เช่น ใส่ re.IGNORECASE ไว้ใน parameter สุดท้าย ว่าเราไม่สนตัวเล็กใหญ่นะ
import re
print(re.search(r"p.ng", "Pangaea", re.IGNORECASE)
🖍️ Wildcards and Character Classes
Character Classes จะถูก define ด้วย square brackets หรือเครื่องหมายวงเล็บใหญ่ [] สำหรับบอก set character ที่เราต้องการ match
ตัวอย่าง
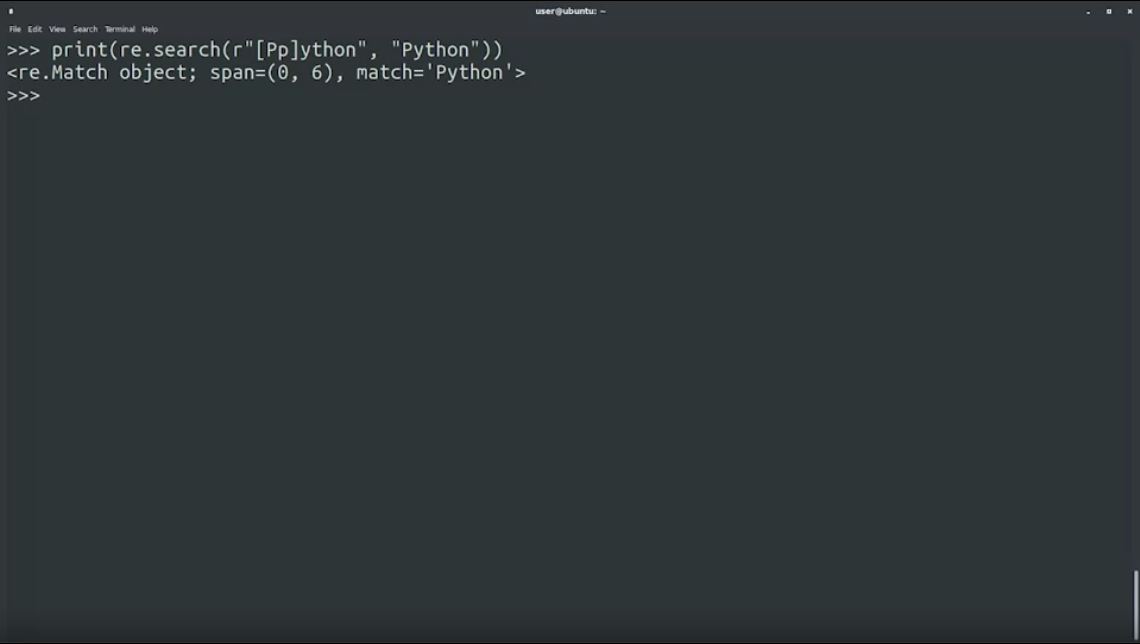
re.search(r"[Pp]ython", "Python"): ต้องการ match กับคำว่า python โดยเป็น P หรือ p ก็ได้ ที่นำหน้า ython
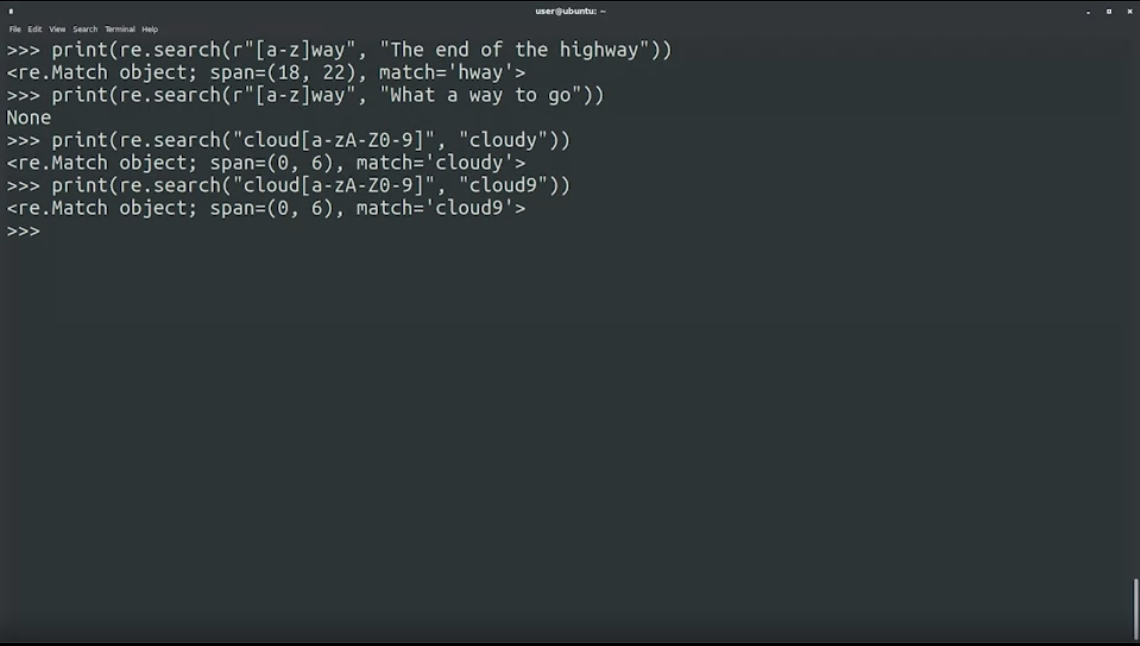
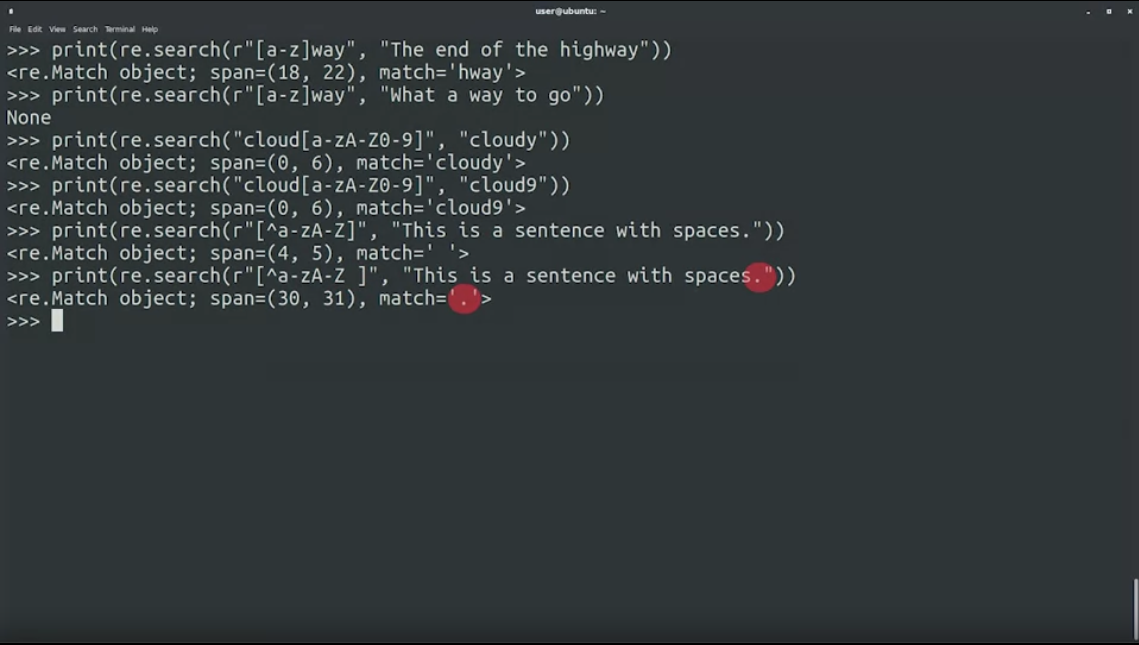
re.search(r"[a-z]way", "The end of the highway"): ทำเป็น range ของ character โดยก้อนนี้นำหน้าด้วย r ลงท้ายด้วย way และตรงกลางเป็นตัวพิมพ์เล็ก a-z ใส่เป็น [a-z] ถ้าอยากได้ uppercase ใส่ [A-Z] ถ้าอยากได้ตัวเลขใส่ [0-9]
print(re.search(r"[Pp]ython", "Python")
print(re.search(r"[a-z]way", "The end of the highway")
print(re.search(r"[a-z]way", "What a way to go") #None
print(re.search(r"cloud[a-zA-Z0-9]", "cloudy")
print(re.search(r"cloud[a-zA-Z0-9]", "cloud9")
re.search(r"[^a-zA-Z]", "This is a sentence with spaces."):ใส่^เพื่อบอกว่าไม่เอา characters ที่ไม่อยู่ใน set นี้ ในที่นี้คือไม่ match กับ a-z และ A-Z
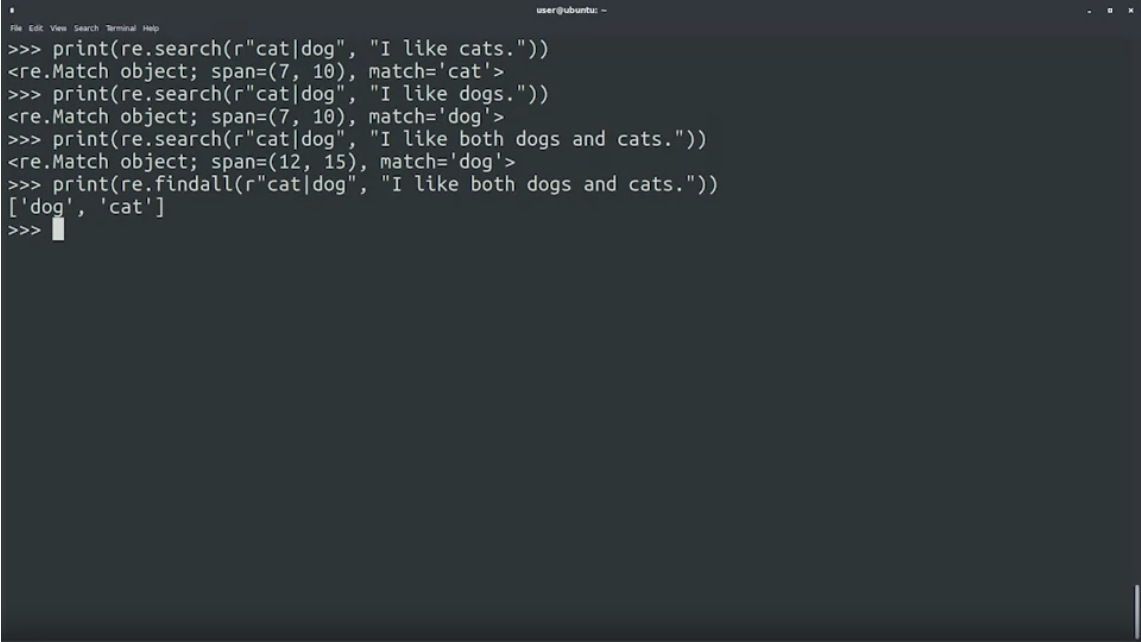
re.search(r"cat|dog", "I like cats."): ใส่|แทน or operator ว่าให้ match อย่างใดอย่างหนึ่ง เช่น cat|dog คำที่ match จะเป็น cat หรือ dog หรือทั้ง cat กับ dog ก็ได้
print(re.search(r"cat|dog", "I like cats.")
print(re.search(r"cat|dog", "I like dogs.")
print(re.search(r"cat|dog", "I like both dogs and cats.")
print(re.findall(r"cat|dog", "I like both dogs and cats.")(re.findall(r"cat|dog", "I like both dogs and cats."):findall()หาที่ match กับ pattern ทั้งหมด คืนค่าออกมาเป็น array คำที่ match
🖍️ Repetition Qualifiers
- concept ของ repeated matches ใช้
.*ติดกัน จะ match character ซํ้า ๆ หลายครั้ง เพราะ syntax*เป็น default greedy behavior มันจะ match กับ string ที่ยาวที่สุด ที่เป็นไปได้
print(re.search(r"Py.*n", "Pygmalion")
print(re.search(r"Py.*n", "Python Programming")
print(re.search(r"Py[a-z*]n", "Python Programming")
print(re.search(r"Py[a-z*]n", "Pyn Programming")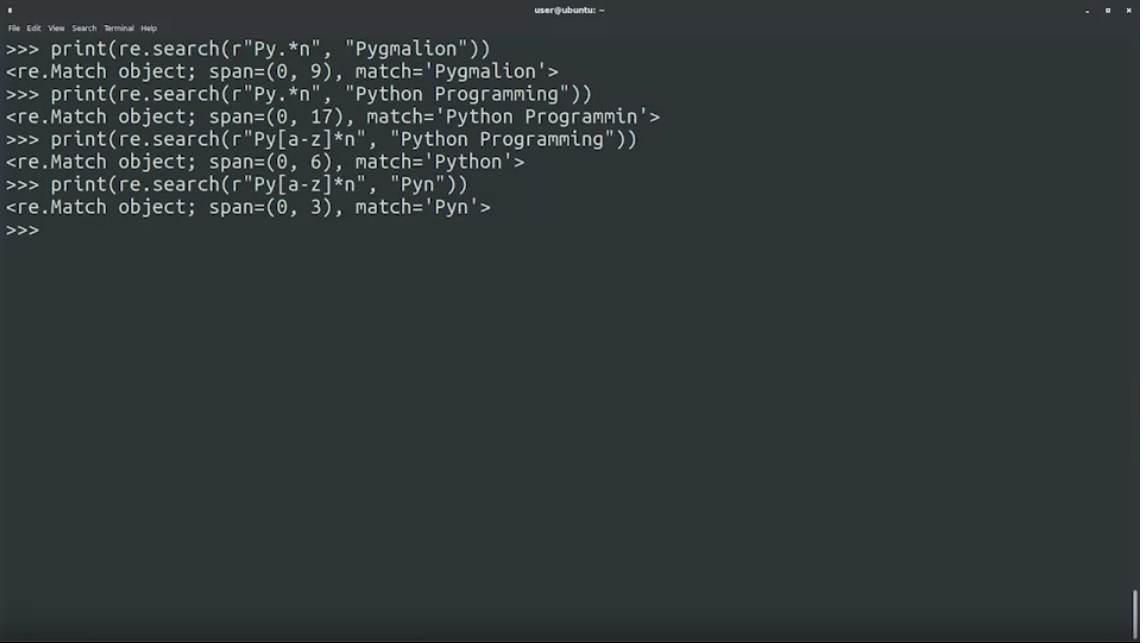
+สำหรับ 1 หรือหลาย occurrence เช่น o+l คืออยากได้ o ตามหลังด้วย l
print(re.search(r"o+l", "goldfish")
print(re.search(r"o+l", "woolly")
print(re.search(r"o+l", "boli")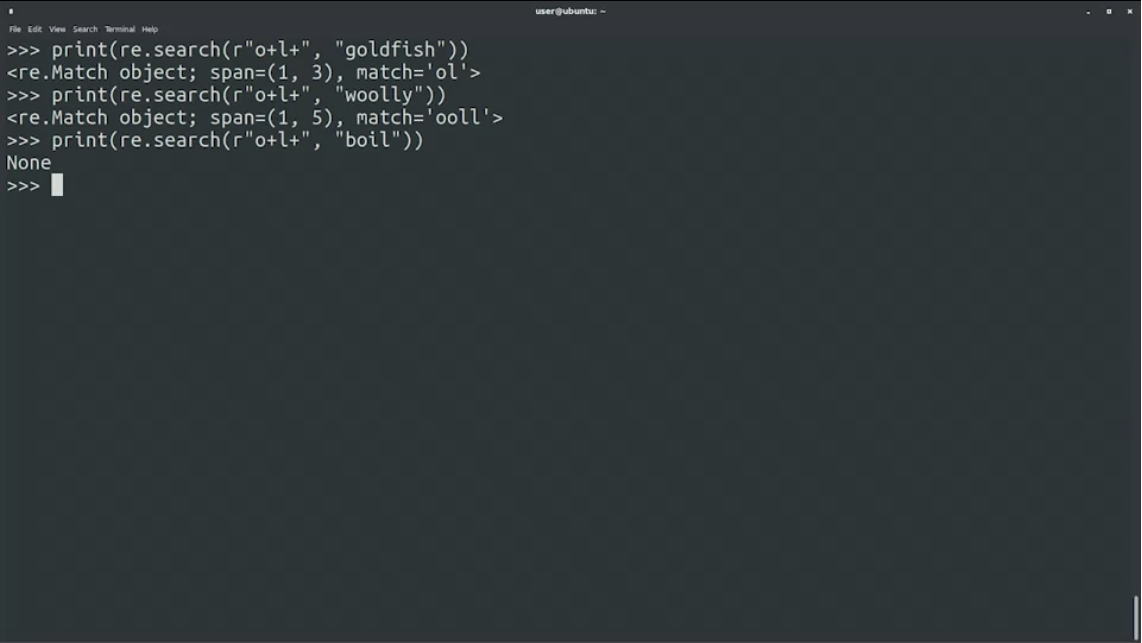
?สำหรับ 0 หรือ 1 occurrence เช่น ต้องการให้มี p อยู่ข้างหน้าหรือไม่ก็ได้ แต่ต้องมี each นะ
print(re.search(r"p?each", "To each their own")
print(re.search(r"p?each", "I like peaches")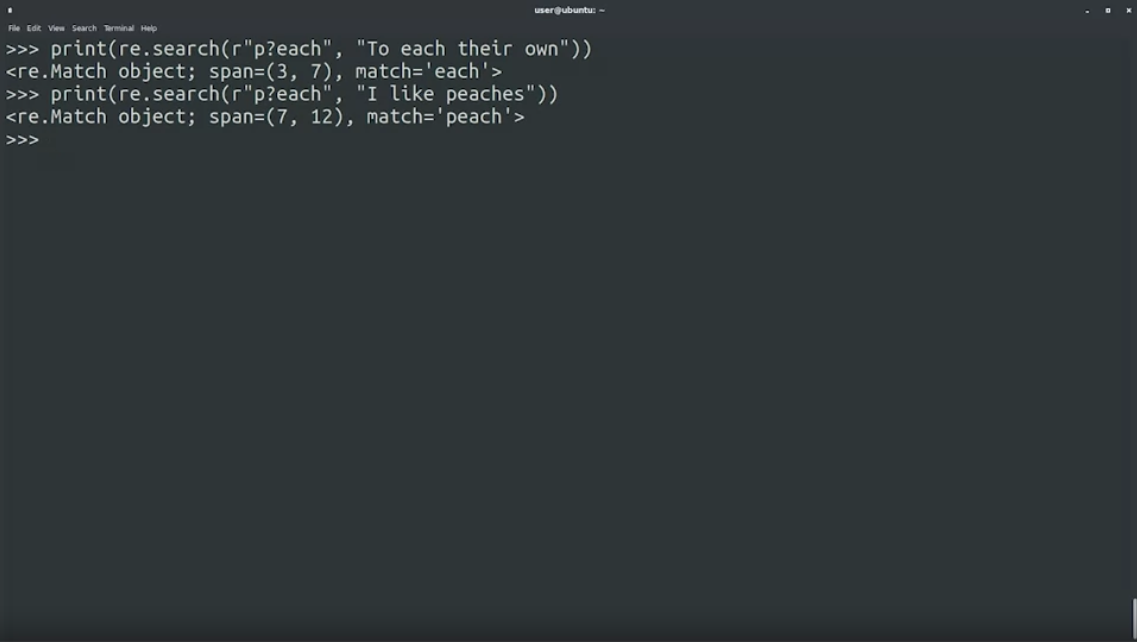
🖍️ Escaping Characters
ตัวอักษรที่มีความหมายพิเศษ ใช้ \ หรือ backslash ใช้ใน RegEx เพื่อบอกว่าเป็นตัวหนังสือธรรมดา จะมี \. หมายถึง จุด อื่น ๆ จะมี \*, \+
ตัวที่ใช้ในการเขียน code
\nขึ้นบรรทัดใหม่\ttab\wหมายถึงตัวหนังสือ ตัวเลข และ underscores\dตัวเลข\swhitespace
🖍️ Regular Expressions in Action
A.*aคำที่เริ่มต้นด้วย A และมี a ข้างหลัง
print(re.search(r"A.*a", "Argentina")
print(re.search(r"A.*a", "Azerbaijan")"^A.*a$”คำที่เริ่มต้นด้วย A และจบด้วย a
print(re.search(r"^A.*a$", "Azerbaijan")
print(re.search(r"^A.*a$", "Australia")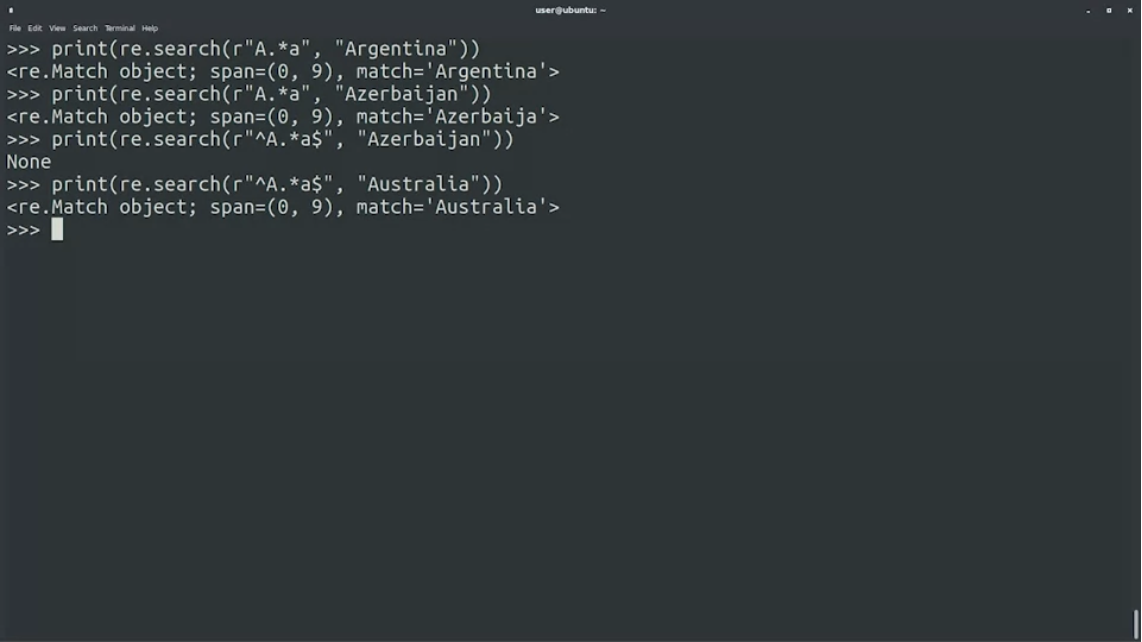
ตัวอย่าง เราต้องการ valid ชื่อที่ประกอบด้วย ตัวหนังสือ ตัวเลย หรือ underscore และไม่นำหน้าด้วยตัวเลข
ตัว pattern ที่ validate ในเคสนี้คือ
^[a-zA-Z_]+[a-zA-Z0-9_]*$
^บอกว่านำหน้า[a-zA-Z_]+นำหน้าด้วย ตัวเล็ก ตัวใหญ่ และ underscore ซึ่งจะ match อย่างน้อย 1 ตัวอักษรขึ้นไป[a-zA-Z0-9_]*ตามหลังด้วย นำหน้าด้วย ตัวเล็ก ตัวใหญ่ ตัวเลข และ underscore match มากกว่า 0 ขึ้นไป$จบด้วยอะไร
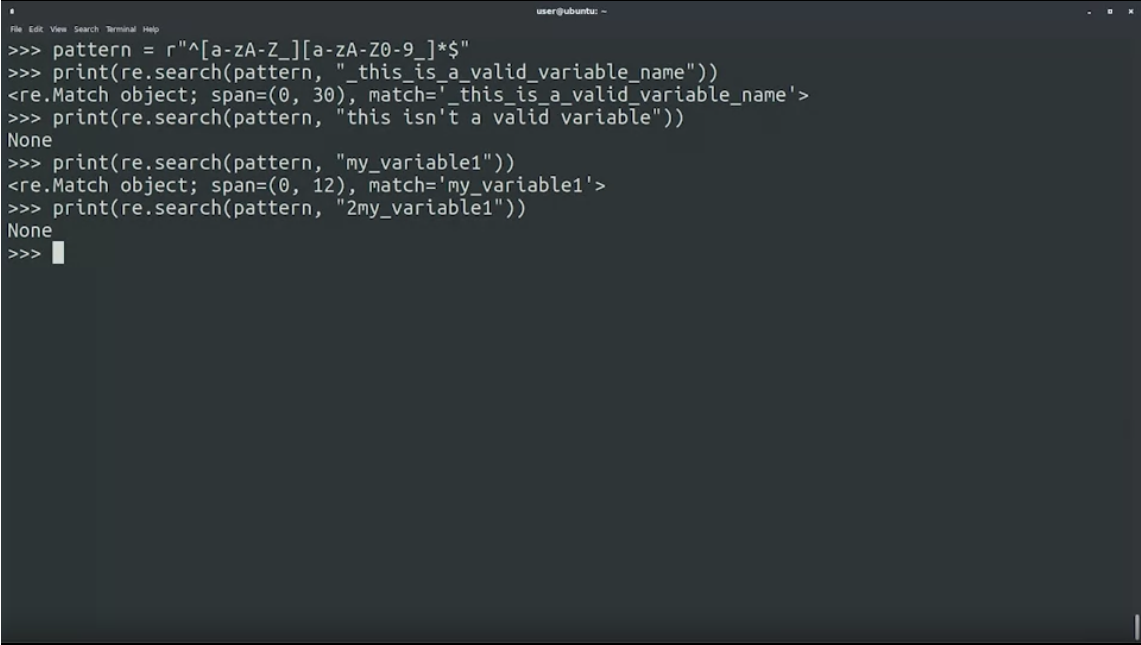
🖍️ Regular Expressions Cheat-Sheet
อันนี้เขาแปะเกี่ยวกับ Regular Expression ของ Python เนอะ


ส่วน tool สามารถลองไปเล่นที่เว็บนี้ได้นะ
Advanced Regular Expressions
🖍️ Capturing Groups
การจัดกลุ่ม ตัวอย่าง คือ มี input เป็น last_name, first_name แล้วเรามาจัดกลุ่มใหม่ โดยสลับมาเป็น first_name last_name สร้าง function ที่มีชื่อว่า rearrange_name()
import re
def rearrange_name(name):
result = re.search(r"^(\w*), (\w).$", name)
if result == None:
return name
return "{} {}".format(result[2], result[1])
rearrange_name("Lovelane, Ada")
rearrange_name("Ritchie, Dennis")
rearrange_name("Hopper, Grace M.")ก่อนอื่นเลย เรามา check name ก่อนว่า match กับ format last_name, first_name ไหม
ถ้าไม่ match คือ None ให้ return name ออกมา
ถ้าใช่ ให้ไปจัด format first_name last_name
จัด output ออกมาเป็น group โดยใช้ groups() โดย result[0] เป็นคำทั้งหมดที่ match ส่วน result[1] เป็นคำแรกที่ match และ result[2] เป็นคำสองที่ match
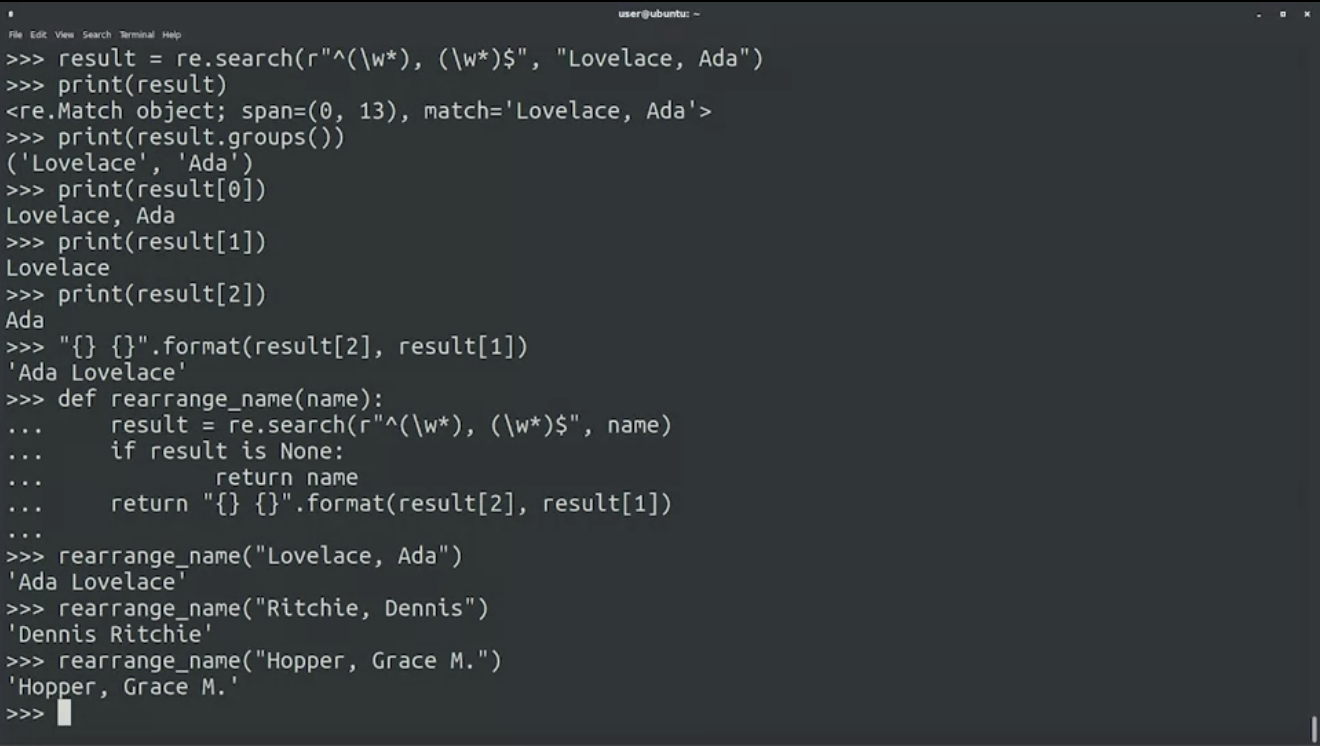
ลองเล่นดูก็ได้ แต่จะมีเคสที่มีชื่อกลาง ผลลัพธ์ที่ได้มันควรจะเป็น Grace M. Hopper มากกว่า เราจึงต้องเปลี่ยน RegEx เป็น "^([\w .-]), ([\w .-])$" เพื่อครอบคลุมทุกเคส
import re
def rearrange_name(name):
result = re.search(r"^([\w \.-]), ([\w \.-])$", name)
if result == None:
return name
return "{} {}".format(result[2], result[1])
name=rearrange_name("Kennedy, John F.")
print(name)🖍️ More on Repetition Qualifiers
Numeric Repetition Qualifiers → ใช้ curly brackets {} กับจำนวน character ที่ต้องการ match
Open-Ended Ranges → ใช้ comma , ในการ define เช่น {5,} match อย่างน้อย 5 {,10} match มากสุด 10 {5,10} match 5 - 10
print(re.search(r"[a-zA-Z]{5}", "a ghost"))
print(re.search(r"[a-zA-Z]{5}", "a scary ghost appeared"))
print(re.findall(r"[a-zA-Z]{5}", "a scary ghost appeared"))
print(re.findall(r"\b[a-zA-Z]{5}\b", "A scary ghost appeared"))
print(re.findall(r"\w{5,10}", "I reallt like strawberries"))
print(re.findall(r"\w{5}", "I reallt like strawberries"))
print(re.findall(r"\w{,20}", "I reallt like strawberries"))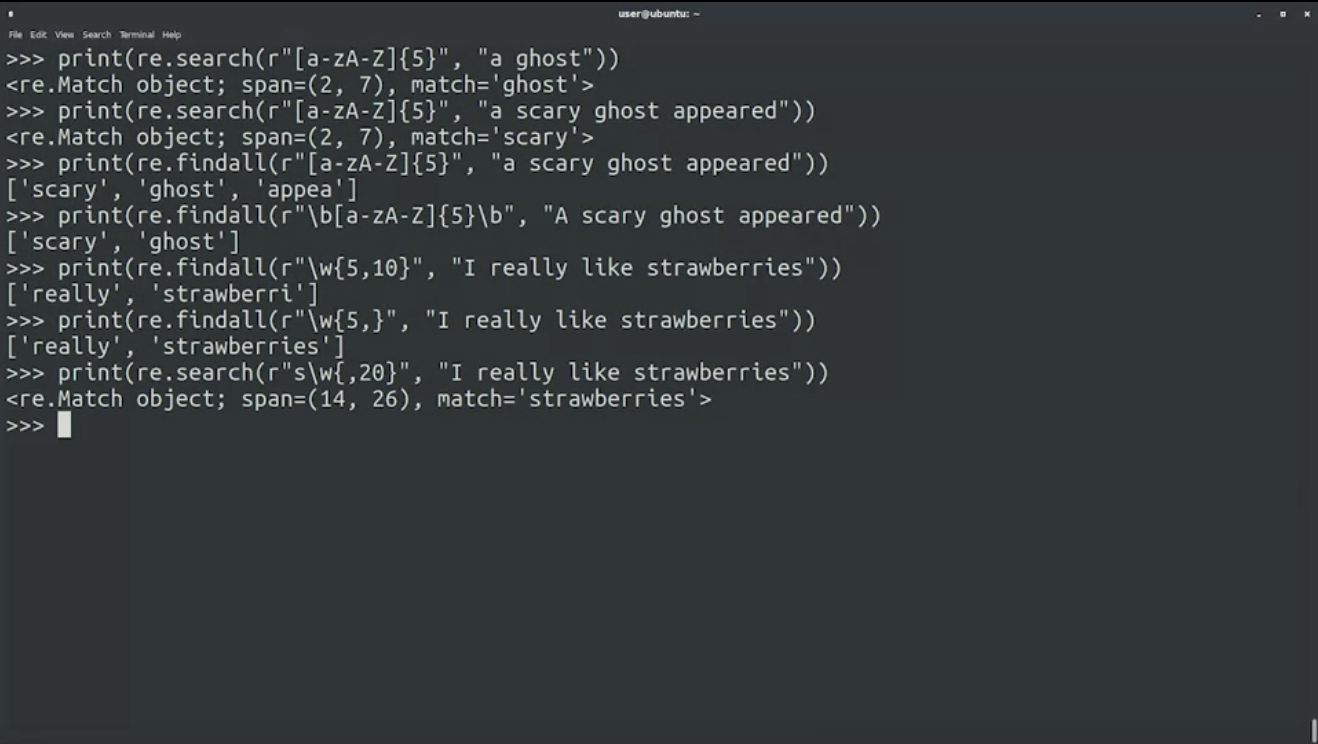
🖍️ Extracting a PID Using regexes in Python
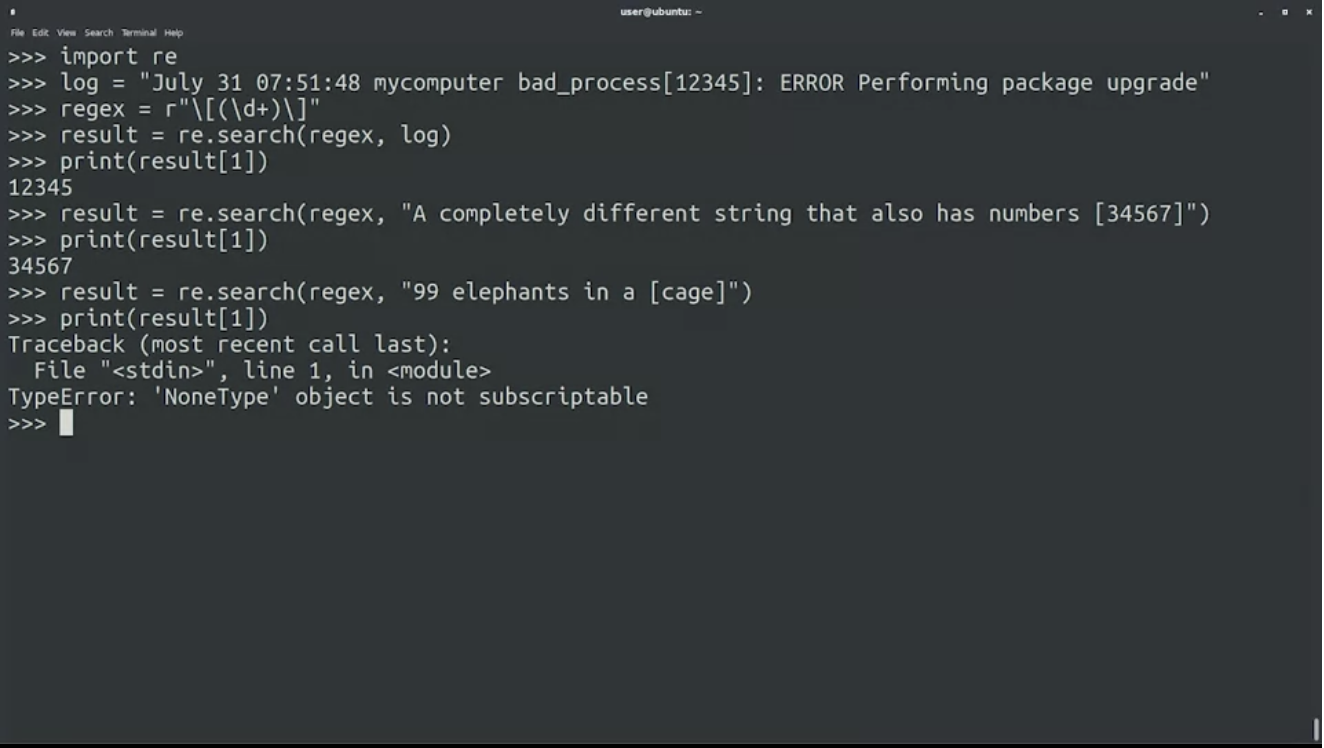
จากตัวอย่างช่วงแรกที่หา Process IDs (PIDs) จาก log lines เราทำเป็น function กัน ชื่อว่า extract_pid()
import re
def extract_pid(log_line):
regex = r"\[(\d+)\]"
result = re.search(regex, log_line)
if result is None:
return ""
return result[1]
log = "July 31 07:51:48 mycomputer bad_process [12345]: ERROR Performing package upgrade"
extract_pid(log)
extract_pid("A completely different string that also has numbers [34567]")
extract_pid("99 elephants in a [cage]")เมื่อ input ไม่ตรง format ก็ควรจะ None แต่ดันเป็น error exception เป็น Handling Potential Errors
ดังนั้นเรามา handle ให้ถูกต้องกัน เราใช้ split() ในการตัดคำแล้วจะได้ประมาณนี้
import re
def extract_pid(log_line):
regex = r"\[(\d+)\]: [A-Z]{3,}"
result = re.search(regex, log_line)
if result is None:
return None
final = result[0].split()
pid = re.search(r"\d{5}", final[0])[0]
return "{} ({})".format(pid, final[1])
print(extract_pid("July 31 07:51:48 mycomputer bad_process[12345]: ERROR Performing package upgrade")) # 12345 (ERROR)
print(extract_pid("99 elephants in a [cage]")) # None
print(extract_pid("A string that also has numbers [34567] but no uppercase message")) # None
print(extract_pid("July 31 08:08:08 mycomputer new_process[67890]: RUNNING Performing backup")) # 67890 (RUNNING)
🖍️ Splitting and Replacing
split()ตัดคำด้วย character ที่เราต้องการ ใส่วงเล็บครอบคือตัดเอามาด้วย
re.split(r"[.?!]", "One sentence. Another one? And the last one!")
re.split(r"([.?!])", "One sentence. Another one? And the last one!")
replace()แทนที่ด้วย character หรือคำที่เราต้องการ เช่นreplace(" ", "")แทนที่ space ด้วย emptysub()คล้ายreplace()
re.sub(r"[\w.%+-]+@[\w.-]+", "[RECACTED]", "Received an email for [email protected]")
และใช้ในการ rearrange ได้ แทนการใช้ groups() ง่ายกว่าการทำ function เมื่อกี้เยอะ
re.sub(r"[\w.-], [\w.-]$", r"\2\1", "Lovelace, Ada")
🖍️ Advanced Regular Expressions Cheat-Sheet
ทั้งหมดก็จะประมาณนี้เนอะ
ติดตามข่าวสารตามช่องทางต่าง ๆ และทุกช่องทางโดเนทกันไว้ที่นี่เลย แนะนำให้ใช้ tipme เน้อ ผ่าน promptpay ได้เต็มไม่หักจ้า
ติดตามข่าวสารแบบไว ๆ มาที่ Twitter เลย บางอย่างไม่มีในบล็อก และหน้าเพจนะ
สวัสดีจ้า ฝากเนื้อฝากตัวกับชาวทวิตเตอร์ด้วยน้าา
— Minseo | Stocker DAO (@mikkipastel) August 24, 2020